What is Site Reliability Engineering (SRE) and How to Build a Reliable Product
 Vadim StrukProduct Manager and Head of Business Analysis at Relevant Software
Vadim StrukProduct Manager and Head of Business Analysis at Relevant Software
Companies like Amazon, Google or Microsoft lose zillions of dollars every minute their systems are down, so they had to find a way to ensure redundancy, fault tolerance, and uninterrupted customer experience. The answer to this challenge is Site Reliability Engineering (SRE). What is SRE, you ask? Read on to get the gist of what SRE is about, how to implement it in your organization, and how to build a reliable product using SRE.
What is Site Reliability Engineering (SRE)?
The idea of SRE was introduced by Ben Traynor, VP of Engineering at Google, in his book “SRE at Google.” You’re welcome to read it (several times), but who has the time? So, we decided to provide you with the gist of the SRE methodology in this article and describe its basic principles and applications.
According to Mr. Traynor, “SRE is what happens when developers have to design and operate an engineering function.” Here’s what he meant: SRE is a paradigm of building systems in a way that maximizes reliability, tracking the results, and constantly adjusting and improving the workflow. It is vital for decreasing the number of incidents in production and implementing prescriptions and procedures that result in measurable performance improvements.
By putting engineers in direct contact with their software in production, along with customer and peer-to-peer feedback from users and colleagues, SRE provides invaluable input and incentive for continuously improving the quality of software and the infrastructure that runs it.
The History of SRE at Google
If you still can’t wrap your head around what SRE is, let’s see how SRE is implemented at Google.
At Google, SRE is a set of practices, workflows, and policies aimed at setting service reliability goals, assessing efficiency, and improving services as needed. Now that sounds like a plan you can attach KPIs to, doesn’t it?
The reason for the need of SRE arose from the fact that Google had to constantly update its vast array of products and services while ensuring their uninterrupted availability. Developers wanted to push updates to production, while Ops engineers wanted to have as little issues as possible. This created an apparent conflict that resulted in everlasting debates and attempts to sneak around the processes.
This was when Mr. Traynor suggested a series of steps that later formed the basis of the SRE methodology:
- Since 100% service uptime cannot be guaranteed, there was an SLA in place, ensuring 99,9% uptime. The remaining 0,1% is the budget for error that could be easily transformed into minutes of downtime, faulty releases requiring rollbacks, etc. So, once the monthly quota was out — all the releases were halted. This step made engineers think twice before pushing something to production and ensured they were writing clean, reliable code.
- Developers had to dedicate at least 5% of their work time to performing Ops responsibilities (answering on-call requests, dealing with tickets, monitoring service performance, etc.). This resulted in the “you built it — you run it” motto, which is now one of the foundations of the DevOps culture. This way, engineers had to get their hands dirty and fix the issues their code caused, continually working with their code in production.
- Developers and the SRE team had a shared recruitment pool, so if the engineering team required another specialist, the SRE team had one less to hire, and vice versa. More than that, the SRE team had the upper hand in recruitment as SRE specialists already knew how to code, knew the product, had their ideas on how to improve it, and knew the workflow.
- Google had blameless postmortems. When something crashed, it was not someone’s fault but an indicator of a system flaw in need of fixing. This bolstered experimenting, which propelled innovation.
These basics created a win-win incentive for both teams to write better code and deliver better services since they were the ones responsible for running them.
SRE vs. DevOps
At this point, you might think SRE is like DevOps. Nope.
DevOps is the culture of automating repetitive software delivery processes to minimize the risk of human error and the effort needed to consistently provide products and services. It is also a mindset of collaboration between developers and the Ops team to make Ops engineers the final judges on all decisions (because they have to deal with the production environment most of the time). Implementing DevOps means decreased development time, reduced numbers of bugs, automation of updates and rollbacks, and more.
Thus, while DevOps is centered around automating repetitive operations to minimize the routine and maximize the performance, SRE is centered around ironing out inconsistencies in the infrastructure and workflows to ensure the reliability of services.
See also our detailed guide on hiring a dedicated DevOps engineer.
Why is SRE Important?
SRE implementation provides significant benefits:
- Decreased mean time to repair (MTTR) and mean time between failures (MTBF)
- Faster delivery of product updates and bug fixes
- Deceased risk of human error due to automation
- Decreased employee burnout as Ops’ tasks become improvements, not firefighting
- Alignment of effort between the developers and the SRE team since they’ll be sharing the same goals
- Increased security and compliance
- Balanced operational requirements
SRE Principles
Now that you know the history of SRE and why it’s not the same as DevOps, let’s take a look at the basic SRE principles you need to instate at the beginning of your SRE journey:
- Build DevOps CI/CD processes to automate infrastructure scaling.
- Cap the Ops load: SRE is only 50% of dealing with the toil. At least 50% must be dedicated to improving the system, not putting out fires.
- The development team should handle at least 5% of the Ops workload. If the load grows due to the developers’ fault, they deal with any excessive tasks.
- Create a Service Level Agreement (SLA), Service Level Objectives (SLOs), and Service Level Indicators (SLIs) for your services and measure system performance against them.
- Instate an error budget to control the velocity of pushing changes into production against quality.
- Implement in-depth monitoring to observe latency, saturation, traffic, and errors.
- Write response scenarios for handling issues based on clear symptom-based alerts. Prepare automated runbooks covering each scenario and test them regularly to keep the team skills sharp.
- Have blameless postmortems and correct all errors found.
- Have a shared recruitment pool for SRE and engineering teams. Allow SREs to grow to developers.
The list is not exhaustive, so feel free to add the things that work for you.
Typical SRE Team Composition: Roles and Responsibilities
Seems too good to be true? Well, it worked for Google and many industry-leading companies across the globe — but you have to understand what SRE team composition you need based on your market niche and stage of operational maturity.
Roles
The typical roles in an SRE team are:
- SRE Team Lead. Forms work scope for every other team member; participates in infrastructure architecture design and workflow updates.
- System Architect. Responsible for building transparent, replicable, and scalable infrastructure that ensures the reliability of services.
- SRE Infrastructure Engineer. A person with 50% Dev tasks and 50% Ops tasks who works on solving the current issues as well as planning and implementing system updates.
- Release manager. Responsible for planning and executing code releases and rollback strategies if needed.
- Monitoring engineer. A person responsible for monitoring four “golden signals” — latency, saturation, errors, and traffic.
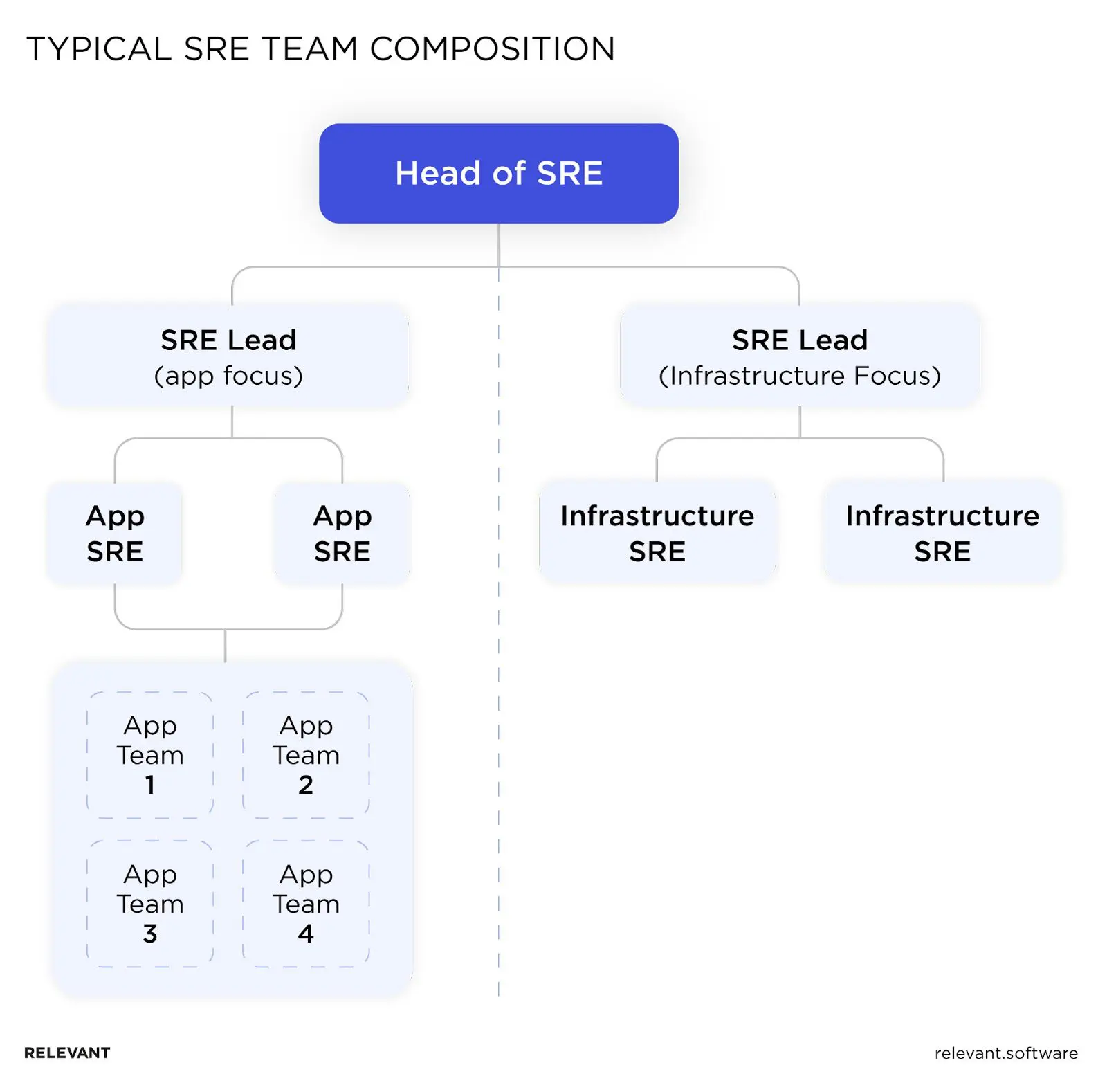
These roles are flexible and can grow into or replace one another based on your scope of tasks. The responsibilities SRE teams perform mostly depend on the stage of your SRE journey.
Beginner SRE
Here are the basic prerequisites for a productive SRE team:
- The shared staffing pool is approved and funded, so the Dev and SRE teams can expand as needed.
- The team dedicates at least 50% time to system improvements and other 50% time to dealing with the Ops workload.
- Up-to-date documentation is available for releases, rollbacks, failovers, and tearing down the infrastructure.
- Canary releases are in place as a part of SLO.
- Rollback scenarios are ready (unless it is a mobile app, where rollback is a non-trivial task).
- Operational SRE runbooks must be present and updated constantly.
- Disaster recovery exercises take place regularly.
- SRE team has a core project that is not related to immediate developer goals but critical for long-term performance improvement (infrastructure optimization, removal of performance bottlenecks, etc.).
- There is sufficient on-call load to perform weekly incident response procedure training.
- C-level buy-in and approval for the SRE charter.
- Regular meetings between the SRE and development team leaders to share information and validate goals.
- Developer-requested projects are planned and executed jointly by the SRE and development teams, so their positive results are immediately visible to both.
While the beginner level SRE scope of tasks might seem a bit overwhelming, all it actually takes to implement is dedicating some time and effort to establish procedures.
Intermediate SRE
Intermediate SRE teams are more mature and begin to take a proactive approach, trying to solve issues before they arise. Here are their prerequisites:
- Regular reviews of SRE projects and outcomes with business leadership.
- Regular assessments of SLI, SLO, and SLA terms with business leadership.
- Scaling the impact. When the positive effects of SRE begin to show, the operational load on the SRE team starts falling, so dedicating 50% of the time to Ops becomes unnecessary. This is when the SRE engineers start scaling the impact of their team beyond adding more services to the scope.
- An automated rollback mechanism for canary releases is in place.
- Regular testing of incident management efficiency is in place using role-playing and automated scenarios.
- Release freeze/unfreeze policy tied to SLO violations is designed and implemented.
- There is a regular overview of all postmortems and action items taken to prevent the results in the future.
- Disaster recovery scenarios are periodically tested against non-production environments.
- The SRE team regularly measures demand vs. capacity and tries to forecast when the demand might exceed the capacity based on historical monitoring data.
- The SRE team is done with putting out the daily Ops fires and starts making long-term infrastructure improvement plans (for one year or more).
At this stage, SRE project results become feasible, and minute monitoring is needed to lay the ground for a lasting company-wide success.
Advanced SRE
These results can be observed in mature SRE teams that are done with infrastructure redesign and concentrate now on maximizing positive outcomes of all IT-related business processes. Here’s what makes an advanced SRE team:
- At least several SRE team members can prove a major positive impact of their projects on some business aspects aside from daily firefighting and the routine Ops work.
- The impact of new projects is spread horizontally across the organization, not concentrated on a single business aspect.
- The majority of service alerts are tied to SLO burn thresholds.
- All possible disaster recovery scenarios are automated, and their positive impact is measurable.
- SRE teams don’t have to be available on-call 24/7. They can even be split between two locations, like the USA and Ukraine, with both teams being equally important.
- The SRE and engineering teams share common goals but have separate reporting chains to C-levels to avoid conflicts of interest.
How to Implement SRE
There are three primary ways of SRE implementation, as you can see in the image below. The SRE team can work in tandem with product teams, be spread among them, or be a separate centralized unit.
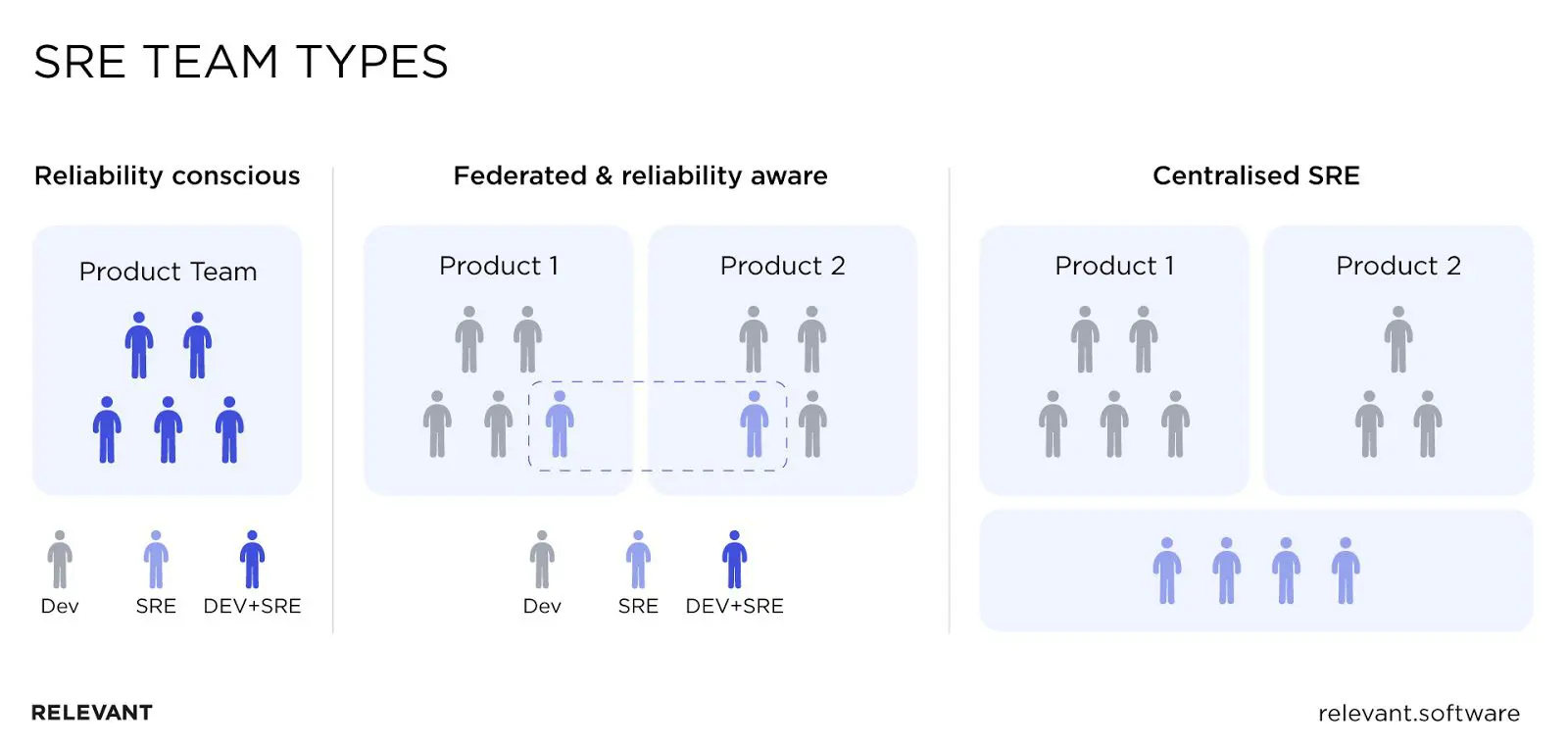
Before you begin implementing SRE, allocate some time from all the parties involved. Gather and discuss the best approach to implementing SRE based on your business specifics. At least one SRE advocate has to be present and able to answer questions, or the project might not even take off.
This is an easy way to start your SRE journey without much investment and organizational change. Plus, it helps test out different SRE models and choose the best fit. On the other hand, it will take you some effort to free up time for many professionals to gather.
[rws-cta id=”9800″]
Speaking of SRE implementation models, here are six of them.
Model 1: Kitchen Sink
In this model, a single SRE team must cover all processes in the organization. It is the most widely used approach, and it allows the team to grow organically along with the business.
Pros:
- A single team means there are no coverage gaps.
- A single team can easily spot patterns and similarities between different projects.
- SRE engineers act as a glue between various projects, delivering holistic solutions based on disparate software pieces.
Cons:
- There is no SRE charter, or it encompasses all possible tasks, leading to the risk of the team getting too much on its plate.
- If a business grows exponentially and no other SRE model is accepted, the team runs the risk of moving from a company-wide innovator to a contributor in many minor improvements. This can be avoided by implementing multi-tiered SRE.
- Any issues within the SRE team can cause damage to the whole business.
Best used: In smaller companies with a single or a couple of products and one or two customer journeys. In this case, the SRE needs are present, but the scope is not enough to justify more than a single dedicated SRE team. This is the approach taken by most technology providers like Relevant Software. It covers all customer needs and provides end-to-end SRE services.
Model 2: Product/App
Such SRE teams dedicate their effort to improving the reliability of a single mission-critical product or application at a time.
Pros:
- Provides a clear link between a business objective and how the team applies its efforts.
Cons:
- When the company grows and adds more products or services to its portfolio, it will also have to build new SRE teams for those offerings. This might result in infrastructure duplication and loss of process consistency.
Best used: By large companies that cannot cover the needs of all their products/services with a single SRE team.
Model 3: Infrastructure
Just like the DevOps teams, the infrastructure SRE teams are centered around improving the job quality and performance of the rest of your business. Through automating repetitive actions and removing structural and procedural bottlenecks, such teams speed up software delivery.
Pros:
- Ensuring continuity in maintaining customer-facing products and services across the business.
- The SRE team focuses on defining Infrastructure as Code to greatly simplify the work for developers, testers, and Ops.
Cons:
- Like with Kitchen Sink, any issues within such a team can harm the entire business.
- Lack of direct contact with customer feedback may result in infrastructure improvements that aren’t critical to a positive end-user experience.
- Once again, if your company grows quickly, you might need to split a team like this. In that case, the cons of the Product/App SRE teams apply.
Best used: In larger companies with several separate development teams as they will need to issue common standards to uniform the processes across the board. The DevOps team will handle CI/CD, testing automation, and product releases, while the SRE team should ensure reliability.
Model 4: Tools
Such SRE teams mostly concentrate on creating tools and features that help their fellow developers be most productive. However, tool-centered SRE teams lack direct contact with customer-facing reliability issues and might begin solving irrelevant problems. So, they have to put a lot of effort to stay in the loop.
This approach is very similar to the Infrastructure one, so the same pros and cons apply. However, this one does have a couple more drawbacks:
- Constant monitoring is needed to ensure the Tools team doesn’t become the Infrastructure team, and vice versa.
- More tools might mean more issues and more Ops work. This can be avoided by having an SRE charter with a clearly defined scope of tasks approved by the C-level.
Best used: By any company in need of software tools not readily available through DevOps or SaaS platforms.
Model 5: Embedded
When SRE specialists are embedded within development teams, they usually perform hands-on work like changing environment configurations to ensure maximum performance at every step of the SDLC journey.
Pros:
- Helps focus SRE efforts on solving particular pains of a product development team.
- Enables Dev mentoring through a live demonstration of SRE best practices, so Devs begin to apply them in their decision-making from the get-go.
Cons:
- Disparate SRE specialists tend to lose the consistency of practices.
- Mentoring Devs might leave little time for mentoring junior SREs.
Best used: When starting an SRE journey to empower adoption and speed up transformation. However, this is a limited time approach that must be later replaced with other models.
Model 6: Consulting
While being quite similar to the Embedded model, the Consulting SRE approach tends to avoid actively changing the existing code and infrastructure configuration. Instead, such specialists build tools that complement the existing processes.
Pros:
- Helps scale the impact of SRE outside of the initial project scope.
- Can be performed by outside SRE experts.
Cons:
- Without in-depth knowledge of the product and infrastructure, such solutions might have little actual impact — or lead to troubles if misapplied.
Best used: Before beginning your SRE implementation to get a grip of SRE best practices. Alternatively, when your company is too large to cater to all its operational needs using only the in-house SRE potential.
Common Practices
There are two standard practices that have a significant impact, regardless of the SRE model chosen:
- Standards and practices. The SRE team should instate, use, and promote a set of reliability standards and practices. When the entire organization follows it, the volumes of toil and repetitive incidents drop, and the customer experience is greatly improved.
The SRE team should facilitate the adoption of those standards both by personal example and by mandatory compliance requested by business leaders. - Tiers of SRE service. A single person cannot be an expert in everything, be 100% productive 40 hours a week, answer any question, and solve any issue in under a minute. This is why the best approach to SRE (as well as any other support) is making it tiered:
– Tier 0: consulting, no dedicated SRE staff
– Tier 1: dedicated work on some projects
– Tier 2: on-call SRE work with dedicated time
This way, issues can escalate to appropriate levels of SRE seniority and be solved quickly and efficiently.
The Bottom Line
We hope this article gave you an understanding of what SRE is, what SRE’s basic principles are, how you can implement SRE in your organization, and how to use it to build a reliable product or service. While initially developed by Google, these recommendations can be applied to any infrastructure and workflow.
Once you decide on the SRE model that fits your business needs best, you’re free to build an internal SRE team or outsource this task to a trustworthy technology partner like Relevant Software. We have ample expertise in supporting large-scale systems using DevOps and SRE best practices and would love to help you out. Contact us today!