How to Extract and Integrate FHIR Bulk Data?
 Vadim StrukProduct Manager and Head of Business Analysis at Relevant Software
Vadim StrukProduct Manager and Head of Business Analysis at Relevant Software
When healthcare moved to the digital world, medical organizations and regulators faced the issue of accessing large datasets of health information. The major obstacle was the very complex process of extracting data from Electronic Health Records (EHRs), the main source of clinical data. This task was often beyond the capabilities of many healthcare institutions. Moreover, the non-standard formats of EHR systems made data integration and analysis too expensive and time-consuming. The HL7 FHIR Bulk Data Access API has changed that.
So, what impact bulk FHIR API can bring to individual medical institutions and the sector as a whole? How does it work, and why is it considered a game-changer for health information effortless extraction at scale? Providing HL7 FHIR services for years, we’ll share our expertise on this topic to answer all these questions.
What is FHIR Bulk Data?
Bulk FHIR data API, often called Flat FHIR API, is a standard designed to simplify population-level data extraction from healthcare systems. It empowers researchers, healthcare providers, and public health authorities to access and export vast amounts of patient information from EHR systems at once without special effort.
Unlike the standard FHIR APIs, which primarily focus on exchanging individual patient records, the bulk data export capacity allows for extracting extensive data with just one request. So, instead of creating countless queries for retrieving each patient record one by one, healthcare organizations can now do it with a single request. Moreover, it’s also possible to detail the export requests by specifying necessary FHIR data types and applying filters.
To keep the system running smoothly, the FHIR bulk data API uses asynchronous request processing. It also leverages the SMART on FHIR backend services framework to strengthen security with authentication and authorization protocols. After the data is processed, it’s saved as files that can be downloaded by the client. How long this takes depends on the dataset’s size and how many FHIR resources it has. The data is presented in the efficient NDJSON format, which is better for large amounts of data than the typical search set response.
Benefits of FHIR Bulk Data Extraction
A single improvement in medical organizations’ capabilities to share huge data volumes, which takes less time and resources, provides many advantages. Here are some of them:
- Improved data analysis. Bulk FHIR API converts every piece of information in a consistent, standardized, and easily processed format. Thus, it considerably simplifies the analytic processes, which can be created just once and then be applied universally within the healthcare system using the bulk data export files. Due to the standardization, medical facilities can analyze information at scale.
- Reduced latency. The common way of accessing healthcare data often involves requesting individual patient records one by one, which is time-consuming, especially when dealing with large datasets. By contrast, FHIR bulk data export allows extracting massive amounts of data with a single request, speeding up the process. It’s also more efficient at reducing the delay between requesting data and receiving it.
- Streamlined interoperability. While FHIR implementation allows the sharing of individual patient records, the bulk FHIR API lets healthcare professionals exchange large amounts of data at once. This capability is especially useful for healthcare analytics, research, and population health management to gain insights and health trends from large datasets. For hospitals, it’s beneficial in cases when transferring a patient’s full medical history from one facility to another.
Steps to Extract FHIR Bulk Data
FHIR bulk export isn’t that difficult if you know how to do it right. That’s why we prepared a step-by-step guide to help you retrieve data using FHIR bulk data painlessly.
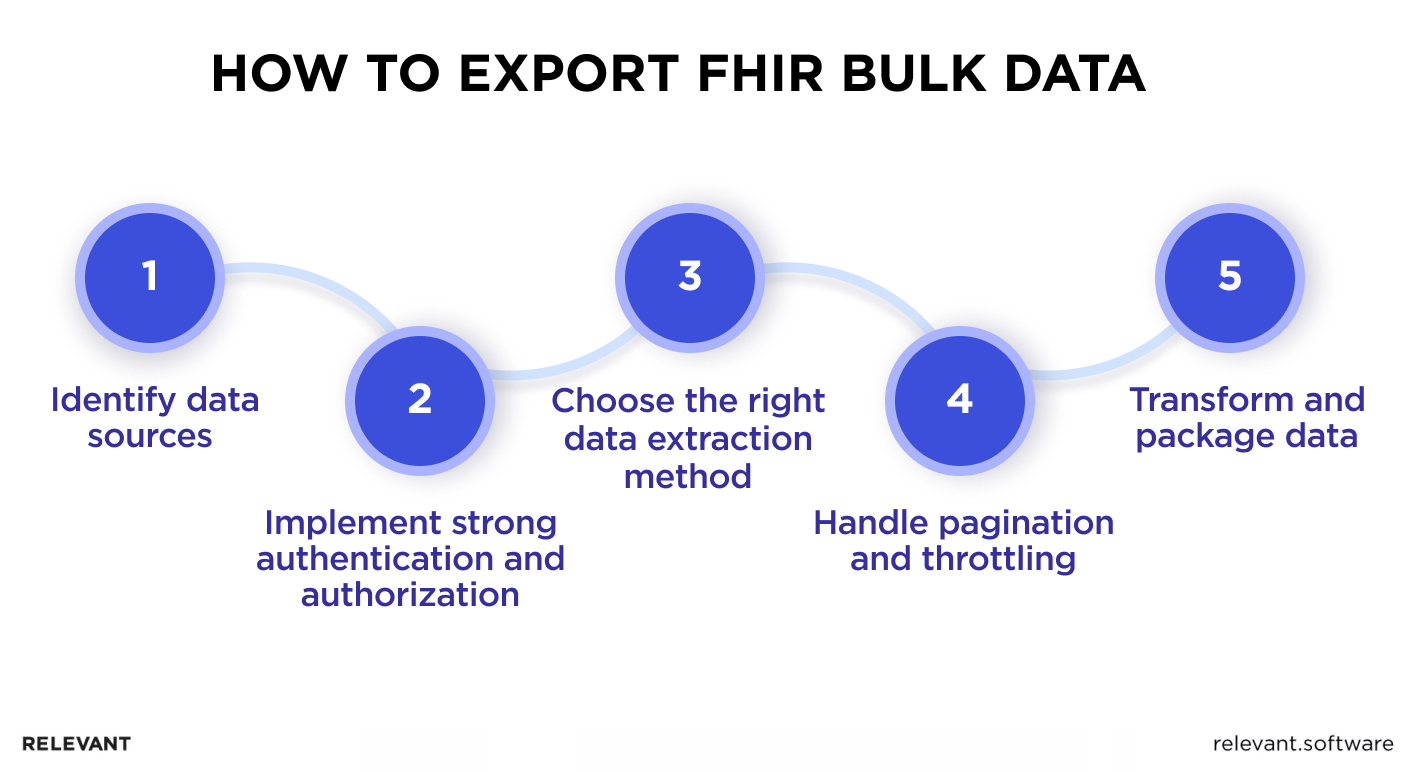
Data Source Identification
First of all, you should know what type of data you want to export (patient demographics, clinical observations, medications, or a combination of these) and where it’s stored.
In the FHIR standard, each data type corresponds to a particular resource category, such as Patient, Observation, or Medication, which helps you narrow the search. Moreover, each FHIR resource has metadata describing the origin, type, and other attributes of the data elements that can give you a sense of which exact file server or database stores the necessary information. You can also use HAPI FHIR bulk import or SMART on FHIR tools that simplify the search through filtering.
Authentication and Authorization
Health data is sensitive, and if it gets into the wrong hands, it could have serious consequences, including the compromise of patient trust and confidentiality. Moreover, healthcare providers have to adhere to strict data access and protection standards, like HIPAA. Non-compliance with them can incur hefty fines and damage reputation.
For these reasons, it’s so important that only the right people have access to health information. Every interaction with FHIR data should be protected with proper authentication and authorization mechanisms. Using secure protocols and multi-factor authentication will check the identity of the user trying to access data and grant it only if they have appropriate credentials.
Meanwhile, role-based access controls for authorization ensure that users can only view or extract data they are permitted to, usually based on their roles. In such a way, FHIR data remains confidential and accessible only to those with the right permissions and used in ways that respect patient rights and regulatory standards.
Choosing the Right Data Extraction Method
Your decision on the method will make a difference in how you retrieve the data, its volume, and other crucial aspects. So, there are several options:

- The export operation is a straightforward way to request a full or partial export of patient records from a FHIR server. It’s ideal if you need to extract large datasets such as data migration or backup. But keep in mind requesting a lot of data at once might put more load on servers, especially if several users request simultaneously. Also, using it for real-time or frequently updated clinical data is not a good idea.
- Search-based extraction allows you to specify particular criteria to find and retrieve the information you need, which can save time and resources for obtaining only relevant data. For instance, if a researcher is only interested in patient records from a certain age group or with a specific condition, they can use the search-based method to extract just that subset of data. So, it offers more precision and flexibility compared to other approaches. Notice that you should have at least some understanding of the FHIR data model to frame precise FHIR bulk queries.
- The subscription method is the best option when you need to receive updates on certain data changes without repeatedly querying the system. Simply put, you ‘subscribe’ to specific criteria, and when data matching your criteria changes or is added, you receive a notification. It’s a perfect fit for monitoring patient data, tracking updates, or applications that rely on up-to-the-minute information. However, this method is barely suitable for extracting large historical datasets.
So, first of all, the choice of the method depends on the purpose of FHIR bulk data export (real-time monitoring or trend analysis of historical data). Then, you should understand what volume of data you want to extract, what frequency of data access you need, and how specific information you’re looking for. These requirements will determine the best option for your case.
Handling Pagination and Throttling
When extracting large quantities of data using bulk FHIR API, two challenges often arise: pagination and throttling. Addressing them is vital as they directly impact the quality and efficiency of the process.
Pagination divides data into manageable chunks or “pages” instead of delivering it all at once. Thus, it helps systems avoid crashes, slowdowns, or being overloaded while generally making core data transmission smoother. Yet, pagination requires careful handling during FHIR bulk export. Since paginated data is spread across multiple pages, there’s a risk of missing out on some pages or retrieving duplicate content. Therefore, you need to track and manage every page to ensure each subsequent request captures the next data page.
Now, what about throttling? API providers set a restriction to limit the number of requests a user can make within a given time frame. The reason is to maintain the server’s performance and prevent misuse. If you exceed this limit during bulk data extraction, the API might temporarily block your access. To avoid such situations, implement a delay mechanism or a rate limiter that will help you space out the requests and stay within an acceptable threshold. By doing so, you won’t overburden the system and will avoid interruptions during data retrieval.
Data Transformation and Packaging
Extracted FHIR bulk data is typically in the NDJSON (Newline Delimited JSON) format, which is, in fact, a series of JSON objects, one per line. It’s useful for bulk extractions, but if you need to process or analyze data further, you should convert it into more common CSV, JSON, or XML formats, supported by most software and analytics tools. Here are a few steps on how to do that:
- Read the NDJSON file. Start by loading the NDJSON file into a programming environment or tool that supports JSON processing. Many programming languages, including Python, JavaScript, and Java, have libraries or modules that can read NDJSON files.
- Parse the data. Once loaded, iterate through each line of the NDJSON file. Each line in an NDJSON file is a valid JSON object. Parse each line as an individual JSON object.
- Transform to the desired format:
- For JSON. You can simply gather each object from the NDJSON file, place them into a list or array, and then save it as a JSON file.
- For XML. Use a suitable library or tools in your preferred programming language to convert JSON to XML. For example, in Python, it’s ‘xmltodict’ and ‘json2xml’, in JavaScript (Node.js): ‘xml-js’ and ‘js2xmlparser’, etc. As you process JSON objects from the NDJSON, change them to XML and add to your document.
- For CSV. Decide which data fields or attributes you want to include. Then, when you parse each JSON object, pull these attributes and add them as a new line in your CSV file.
- Save the transformed data. After converting data into a necessary format, save the results in a new file with the appropriate extension. For instance, if you work with Python, you can use the json, xml, and csv modules for that.
At this moment, your FHIR bulk export data is almost ready for integration into the destined system. The only step left is packaging. You need to organize and group related data elements together to make information easier to move, store, and share. Follow these steps to do that:
- Select a suitable format depending on where the data is heading next. For example, if you want to send it to another department or organization, ZIP or TAR will work best. If it’s for a FHIR bulk import, check what formats it supports, and if you’re dealing with databases, opt for .bak.
- Organize the data. Cluster similar data elements together. Say you have patient information and treatment details; it’s wise to package them separately.
- Include metadata. Add a file or note explaining the data’s content, its source, and when it was packaged.
- Ensure data integrity. Before finalizing, verify that all the necessary information is included without being altered.
- Encrypt if necessary. If the data is confidential, consider encrypting the entire package to protect it.
Integrating FHIR Bulk Data
When large volumes of health information can flow flawlessly using API healthcare systems, it improves patient care delivery and streamlines all clinical operations that rely on data. To achieve that interoperability, we want to share practical recommendations on how to integrate bulk FHIR data into EHR systems or healthcare software solutions.
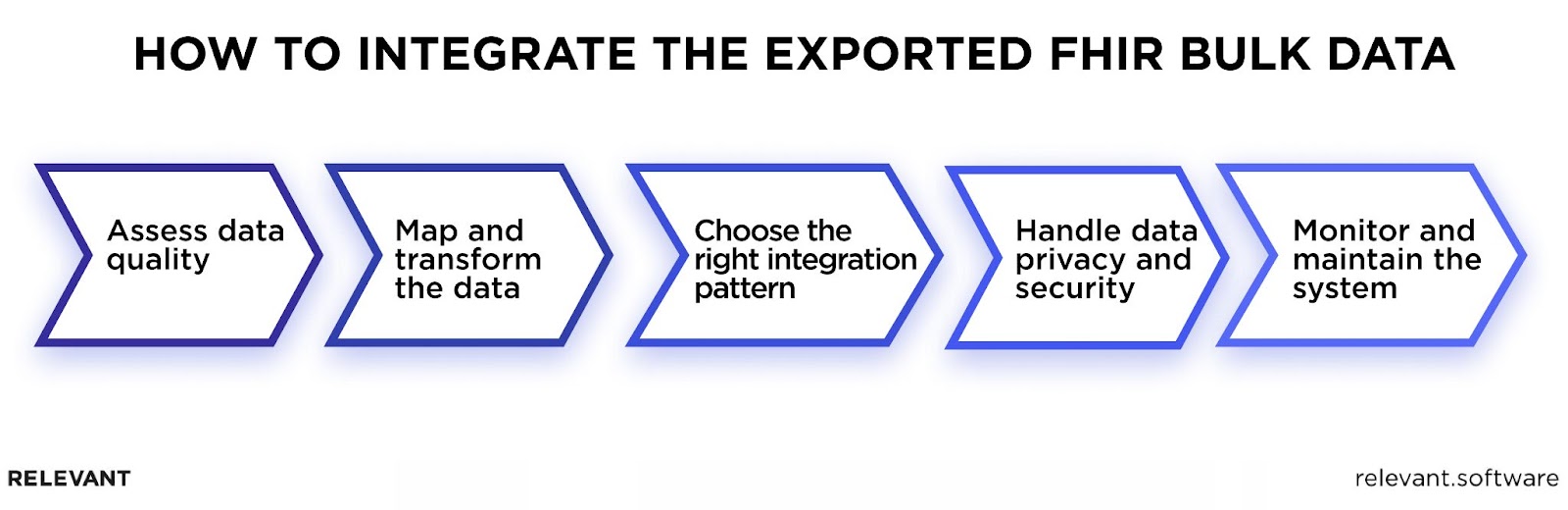
Data Quality Assessment
The data you exported and want to integrate will form the base for many critical decisions on treatment plans, resource allocation, or strategizing. Inaccurate, duplicated, or incomplete core data can have serious consequences. Decisions made using flawed data will affect patient care and operational processes.
Hence, evaluating data quality before integration will help you avoid such negative outcomes. Check the accuracy by comparing some of the exported data with its original source. If you find any inconsistencies, missing values, or data elements that seem out of place, it might mean errors or oversights when you were performing FHIR bulk data export.
Data Mapping and Transformation
Different systems have different ways of organizing and formatting data. Your task is to adjust the extracted data to ensure it’s in the right place (thanks to mapping) and the right shape and format (thanks to transformation). The more accurate you are during these processes, the fewer chances for inconsistencies, system errors, and integration issues.
Start by aligning data fields from the FHIR bulk data with fields of the target system. Each piece of FHIR information has certain labels or identifiers. However, the health system where you want to insert this data can use different labels or structures for the same information. For instance, in FHIR data, a field labeled “DOB” is for date of birth, while the target system may label it as “BirthDate.” You should map this data so that the system understands that both these fields refer to the same piece of information.
So, you have matched the fields. Yet, the actual content within those fields might be in a different format or structure for the target system. Think of it like this: you’ve matched the right boxes (fields) between two systems, but now you should make sure the stuff inside those boxes (the actual data) fits perfectly. For instance, the FHIR data might have dates formatted as “MM-DD-YYYY,” but the health system requires them as “YYYY-MM-DD.” Or, a value in the FHIR data might be in kilograms, but the target system expects it in pounds.
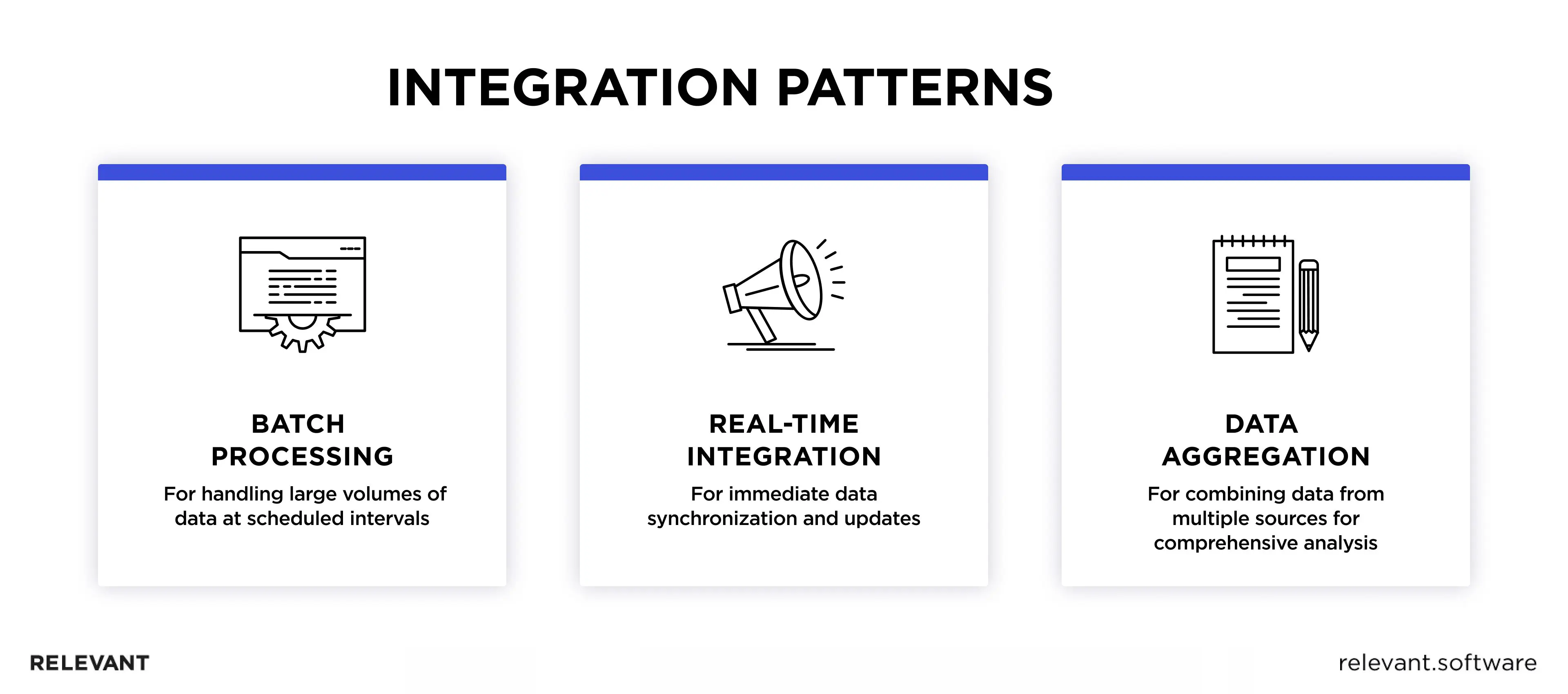
Choosing Integration Patterns
Depending on the IT infrastructures and business needs, healthcare companies pick different types of data integration. Each impacts the way and speed of information exchange between the systems. Let’s quickly dive into each one of those.
Batch Processing means that data is collected and transferred in batches at scheduled periods instead of being moved separately as it comes in. It’s ideal for handling large bulk operations from one file server to another, especially when data is spread across multiple systems. Another advantage is that batch optimizes resource usage and bandwidth thanks to pulling all data at the same time. For instance, large hospitals can use this method to update patient records generated daily by various departments once a day during off-peak hours to avoid system disruptions. However, if doctors need data like morning test results in the afternoon, it won’t be available until the next day.
Real-time Integration. As the name suggests, this pattern transfers or synchronizes data as soon as changes occur. Instead of waiting for a scheduled time, as with batch processing, real-time integration ensures that any update in one system is instantly reflected in another. FHIR API is one of the tools that helps achieve that seamless, real-time integration so crucial in emergency care and real-time patient monitoring. The immediate data exchange empowers healthcare professionals to make quicker and improved decisions regarding patient treatment or urgent interventions.
Data aggregation prepares the data for storing in data lakes or warehouses. It’s a handy approach if you deal with lots of data from multiple sources and need to consolidate and analyze it promptly. Bringing all the patient health data together makes it easier for hospitals to query and search for meaningful patterns in data to identify trends or anomalies. So, data aggregation is the best way for medical organizations to analyze data at scale and draw insights with minimal manual effort.
So, how to select the best pattern? It depends on your organization’s needs. Are you looking for up-to-the-minute data, or are periodic updates what you need? How much information do you need to integrate, and how often? Answering these questions, along with weighing such factors as the existing IT infrastructure and scalability requirements, will help you make the correct decision.
Handling Data Privacy and Security
Healthcare data is sensitive by nature as it contains personal and medical details that, if mishandled or compromised, could incur serious consequences for patients and healthcare providers. What’s more, FHIR bulk data API and other API healthcare solutions have become more widespread, calling for proper data handling at all stages.
For this reason, securing medical information should be your priority. Here’s a quick overview of the most common risks and ways to mitigate them:
- Data breaches. When data moves between EHR systems, it’s more vulnerable to data breaches, especially if not encrypted.
Solution: Encrypt data both at rest and in transit to make it unuseful for cybercriminals, even if they manage to seize it. Also, perform regular system updates and patches to prevent hackers from exploiting known system vulnerabilities.
- Data Corruption. When you integrate or transform data, it can be corrupted as a result of software bugs or transmission errors.
Solution: Implement data validation checks before and after integration to find and correct any inconsistencies immediately. It’s also wise to make backup copies so you can restore the original data.
- Unauthorized access is one of the primary concerns, as the threat can come both externally and internally, with malicious intent or not. Anyway, the access by individuals who have no legitimate reason for that means HIPAA and patient privacy violations.
Solution: The best way to mitigate this risk is to implement a multi-layered approach to accessing data. Set up multi-factor authentication to limit access to only authorized personnel. Then, add role-based access controls to specify and give permissions to users who can view or modify the data. Meanwhile, regular audits and monitoring of system logs will help you spot any unauthorized or suspicious actions.
- Compliance with industry requirements. Any organization dealing with file transfers that include protected health information must strictly follow the HIPAA rules. In a nutshell, it requires maintaining data confidentiality, integrity, and availability.
Solution: In fact, by implementing the security measures we described above will help you closely adhere to HIPAA regulations regarding data protection. What could enhance your efforts is training your staff about the importance of data privacy and the specifics of HIPAA. You should regularly review and update your security protocols and policies to check if you remain compliant. It’s also a good practice to work with a dedicated information security team or officer to help audit your IT systems for HIPAA compliance.
Monitoring and Maintenance
Keeping integrated data consistently flowing between systems without a hitch requires continuous attention and monitoring. You should regularly check the system and all your data streams for inconsistencies, while using automated tools will simplify your task and signal you if they find any data issues. Keeping track of system performance is equally vital for avoiding any slowdowns or issues before they grow into bigger headaches. The same applies to potential errors, be they a failed data transfer or a system glitch; detecting them early can save a lot of trouble down the line.
Besides monitoring, integrated systems need regular maintenance for proper functioning over a period. It’s an ongoing activity that involves taking a variety of measures to help keep the system in good shape:
- Update the system regularly to keep it compatible with the FHIR standard, which is critical for smooth data exchange and interoperability.
- Patching up any software vulnerabilities
- Scanning for viruses or malware
- Making tweaks for better performance, like reformatting and running a system restore, among other things.
Tools and Technologies for FHIR Bulk Data Management
Handling, processing, and analyzing FHIR bulk data is a complex task requiring the right mix of tools and technologies for proper management. Let’s look at some of them and understand how they can simplify interactions with FHIR data sources.
FHIR Data APIs and SDKs
HAPI FHIR is arguably the most comprehensive, simple, yet powerful API for adding FHIR messaging to your app. It’s absolutely Java compatible and licensed under the business-friendly Apache Software License, version 2.0. HAPI FHIR offers a wide range of functionalities like resource validation, easy data parsing, and advanced query building that simplifies data exchange and manipulation. It’s a fairly simple framework to use, but the actual intricacy lies in the maturity of the FHIR specification. You can spend many hours trying to understand how to fill out FHIR resource request objects.
For those in the .NET environment, the FHIR .NET API provides similar capabilities, allowing you to handle data with the same ease but within the .NET ecosystem. In fact, almost every popular programming language has specific libraries that offer pre-built components and mechanisms to simplify FHIR bulk data interactions.
SMART on FHIR is a universal framework that can be used for any programming language due to its rich libraries. Apart from that, you can find documentation and code samples you can use to speed up the creation of interoperable health applications. This framework greatly simplifies the development process by providing pre-built functions for common FHIR data tasks.
ETL (Extract, Transform, Load) Tools
Extract, Transform, and Load (ETL) is a three-stage process used for data integration, migration, and management. It extracts the raw data from one or several sources, transforms it to fit the desired format, and loads it into the data warehouse or database. ETL’s main objective is to make data easy to use for analytics, decision-making, and reporting activities.
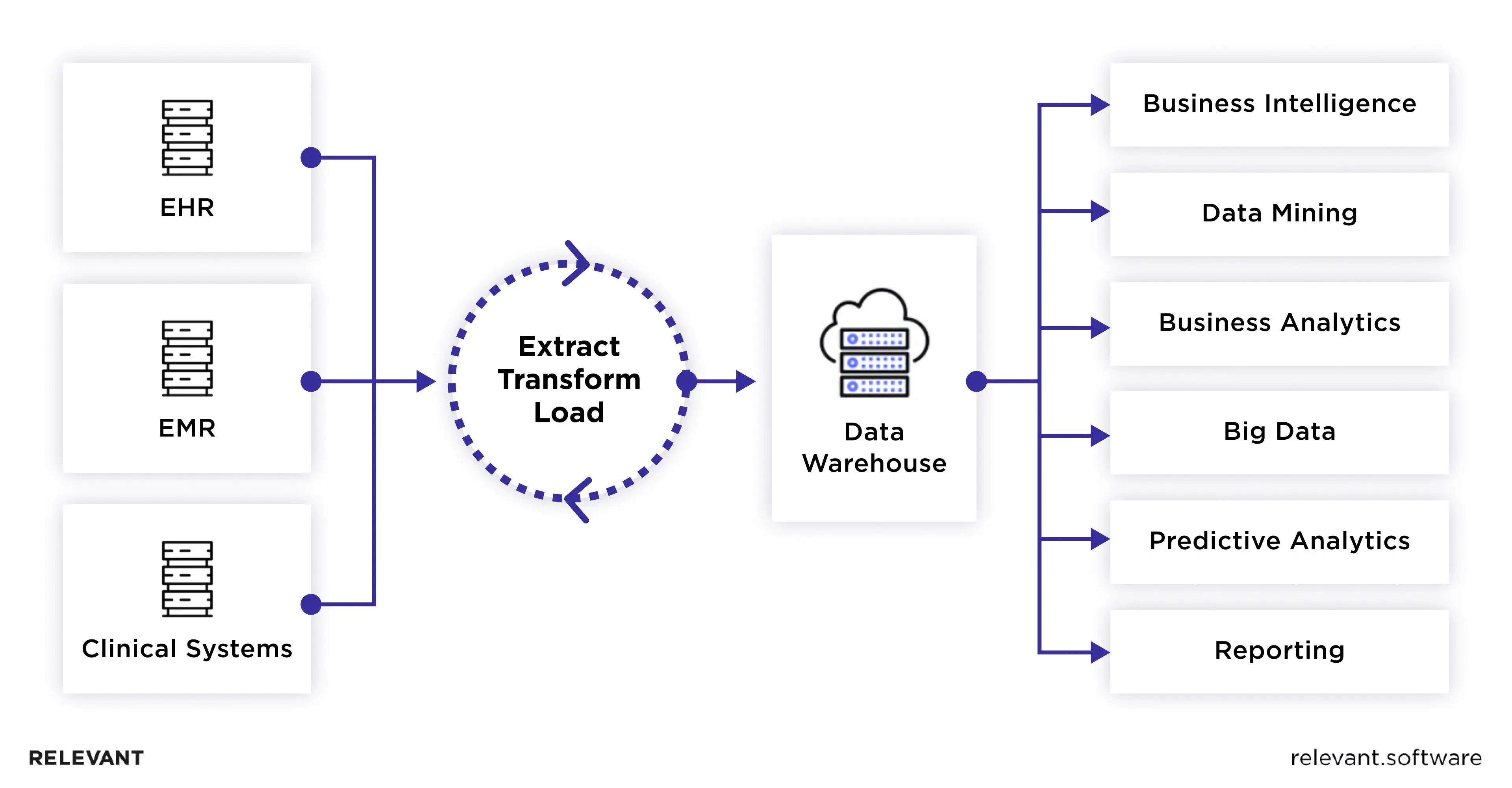
In simple terms, whenever you need to transform data format from one to another, ETL will be handy. For instance, a hospital holds patient information in a CDA (Clinical Document Architecture) format. To integrate this data into a new analytics tool that operates with the FHIR standard, it should be converted from CDA to FHIR, a process easily handled with ETL.
Integration Platforms
When it comes to FHIR bulk data integrations, Mirth Connect is one of the best platforms based on our experience. It supports different data formats, communication protocols, and standards (FHIR, HL7 V2, CDA, etc.), so you can work with the data from any healthcare system regardless of its specific technology or format. The platform allows you to configure the protocols and routing on a user interface, which provides quick connectivity. Mirth Connect also offers an intuitive drag-and-drop functionality for data mapping and transformation. Overall, it’s an excellent, open-source healthcare integration platform.
Redox is another healthcare interoperability solution that is worth attention for its unique approach to integration. It connects different digital health apps through a standardized API and data model, which means that once data is mapped to this model, it can seamlessly interact with any system in the Redox network. Thus, it reduces the time for setting up new integrations since there is no need for custom mapping for each new system. Easy implementation and strong security features are other reasons that speak in favor of this platform.
FHIR Bulk Data: Conclusion
The adoption of FHIR Bulk Data API will grow at a minimum because of the need to meet the 21st Century Act and its requirements to ensure effortless health data access. But with this also comes such benefits as better data analysis at scale, smoother operating healthcare systems, and interoperability. So, in any case, we can expect more medical organizations to use a FHIR API for bulk extractions.
Although exporting FHIR bulk data is way easier now, it still requires some technical skills and knowledge to do it right. If you need help extracting or transferring data or implementing FHIR, you can turn to healthcare software development companies like Relevant. Our experts can provide healthcare IT consulting on how to achieve interoperability and assistance in realizing your FHIR data goals. Contact us to tell us about your data needs and pains.