



Microservices Database Management: What You Need to Know
No one will argue that microservices can be very beneficial for businesses, and the numbers speak for themselves. In 2023, the cloud microservices market stood at $1.54 billion, with predictions reaching $6.04 billion by 2030. That’s quite the leap, right? It’s clear that an increasing number of organizations are turning to microservices database management.
However, it’s not all smooth sailing. Adopting a microservices approach brings its own challenges, especially when it comes to managing a microservices database. What patterns should you use to solve the issues caused by data decentralization? How do services retain data autonomy? Which data architecture to choose for an application?
If you think about using microservices for your next project, these are important things to know. Check out our article to learn more about microservices database best practices and get the answers you need.
The Role of Database Management in Microservices
Database management is key to harmony in microservices applications. At its heart lies the microservices database architecture, a design that ensures each service has its own dedicated database. Think of microservices like a team of chefs in a big kitchen. Each chef has their own workstation, tools, and ingredients. This way, just like one chef’s mess doesn’t spill over to another’s, each service can evolve without affecting others.

But with this decentralization comes challenges, and just like in a kitchen, there needs to be some rules. Database management principles are those rules that ensure all services work well together while maintaining data consistency and security.
Microservices management isn’t just about databases, though. It’s about creating an environment where services can communicate, scale, and recover from failures. And the foundation of this environment is built on robust database principles. When you apply them correctly, you get a resilient and efficient system where data flows smoothly, and services operate at their peak. So, if you consider shifting to microservices, pay special attention to database organization and its principles, as they keep everything ticking.
Microservices database challenges 101
In traditional monolithic applications, there’s a single database where all application’s components share the data. By contrast, in a microservices app, data ownership is decentralized. Every service within the microservices database is autonomous and has its private data store relevant to its functionality. This means that one service can’t modify any data stored inside the other service’s database. And that’s where the problems start.

No matter what kind of application you build, its microservices need to interact and share data. Because if they don’t, you risk having consistency issues like duplicating data. The problem is in microservices, you can’t use ACID (Atomicity, Consistency, Isolation, and Durability) transactions for operations outside a single service. So beware: having private databases for microservices instead of a single shared one makes it challenging to implement queries and transactions that span several services.
5 common data-related patterns and 1 anti-pattern
Let’s take a look at the collection of patterns related to data microservices management.
The Database-per-Service pattern
The core characteristic of the microservices data architecture is the loose coupling of services. To ensure that, every service should have its own data repository. So, building the microservices database architecture almost always requires following the database-per-service pattern, especially in applications that aren’t too complex yet.
Let’s consider an online store where both the Order and Customer Services store information in their individual databases. If you change one database, it doesn’t impact other services. Moreover, other microservices can’t directly access a service’s database. Instead, they access the stored data only by using APIs.

The Saga pattern
Using the Database-per-Service pattern often requires adopting the Saga pattern because sagas are a way of implementing transactions that span services while maintaining data consistency. In microservices integration patterns, instead of traditional distributed transactions (XA/2PC-based), you have to use the sequence of local transactions (aka Saga). Here’s how it works: a single transaction modifies the database and then initiates the subsequent transaction via messaging.
You can choose between two different approaches to coordinating sagas:
- choreography – when event exchanges occur without points of control
- orchestration – when you have centralized controllers.

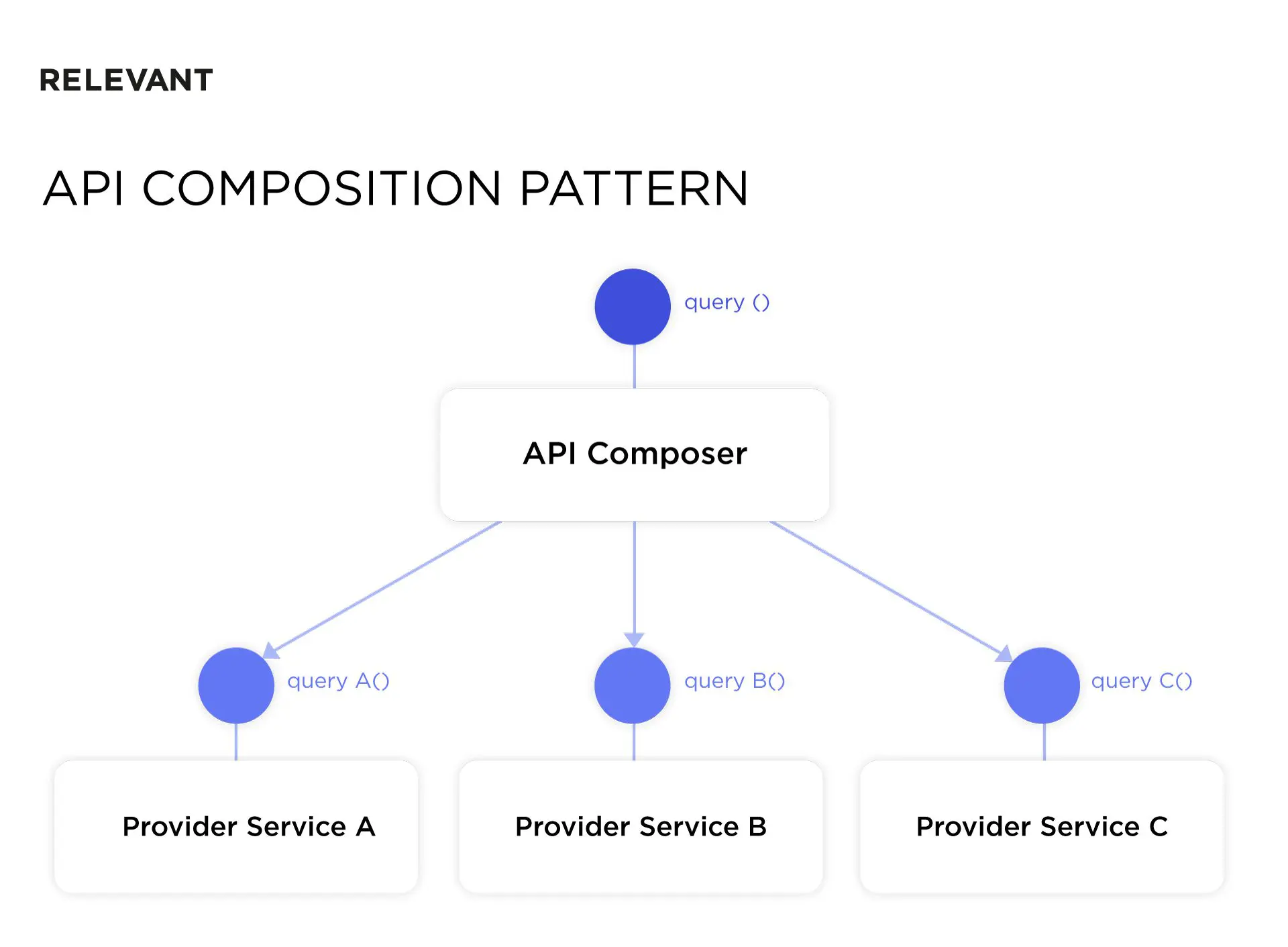
The API Composition pattern
Now, let’s dive deep into how we can retrieve data from multiple services in the pattern database. Traditional querying methods won’t work here. But you can use the API Composition pattern instead. It implements a query by invoking certain services for their data and then compiling all that information. Below, you can see how an API Composer retrieves data from three provider services. In our blog post about APIs, you can find more info on how to choose the perfect API for your next application.
The CQRS pattern
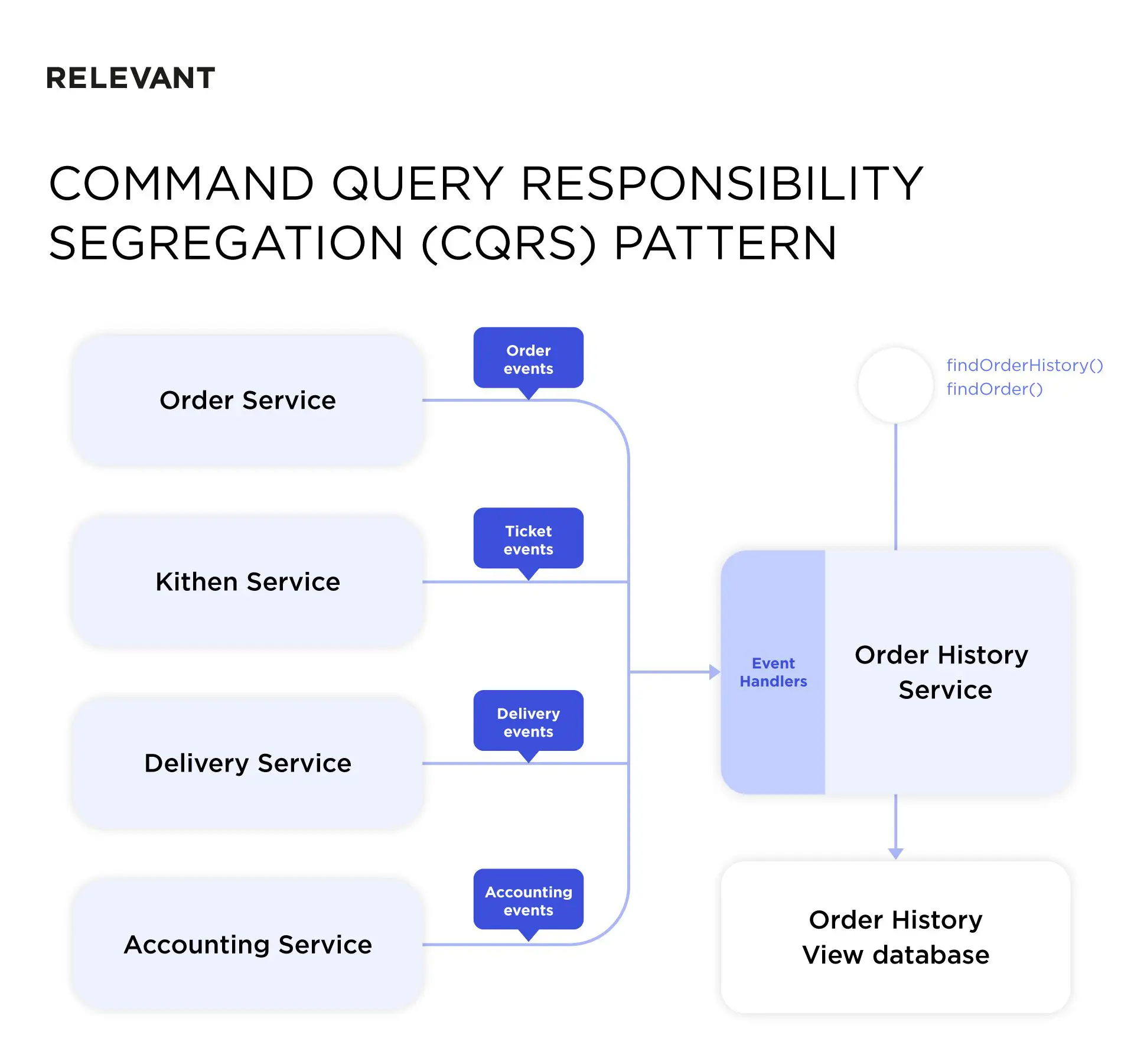
When dealing with a database microservices environment, the command query responsibility segregation (CQRS) querying pattern can help. The thing is, API Composition has some limitations: you can’t use it for complex queries because you’ll get inefficient in-memory joins. It’s also crucial to delineate tasks to prevent service overload. Otherwise, you can get a service that owns data but can’t implement the query operation.
That’s when CQRS will be helpful. It employs view databases to implement queries, allowing the separation of commands from queries. The query-side modules implement queries and keep the data model synchronized with the command-side data model. And as for the command side modules, they manage the operations.
You can use CQRS within a service to define query services. A query service’s API consists of query operations only. It checks a database and keeps it up to date by subscribing to events published by the services that own the data.
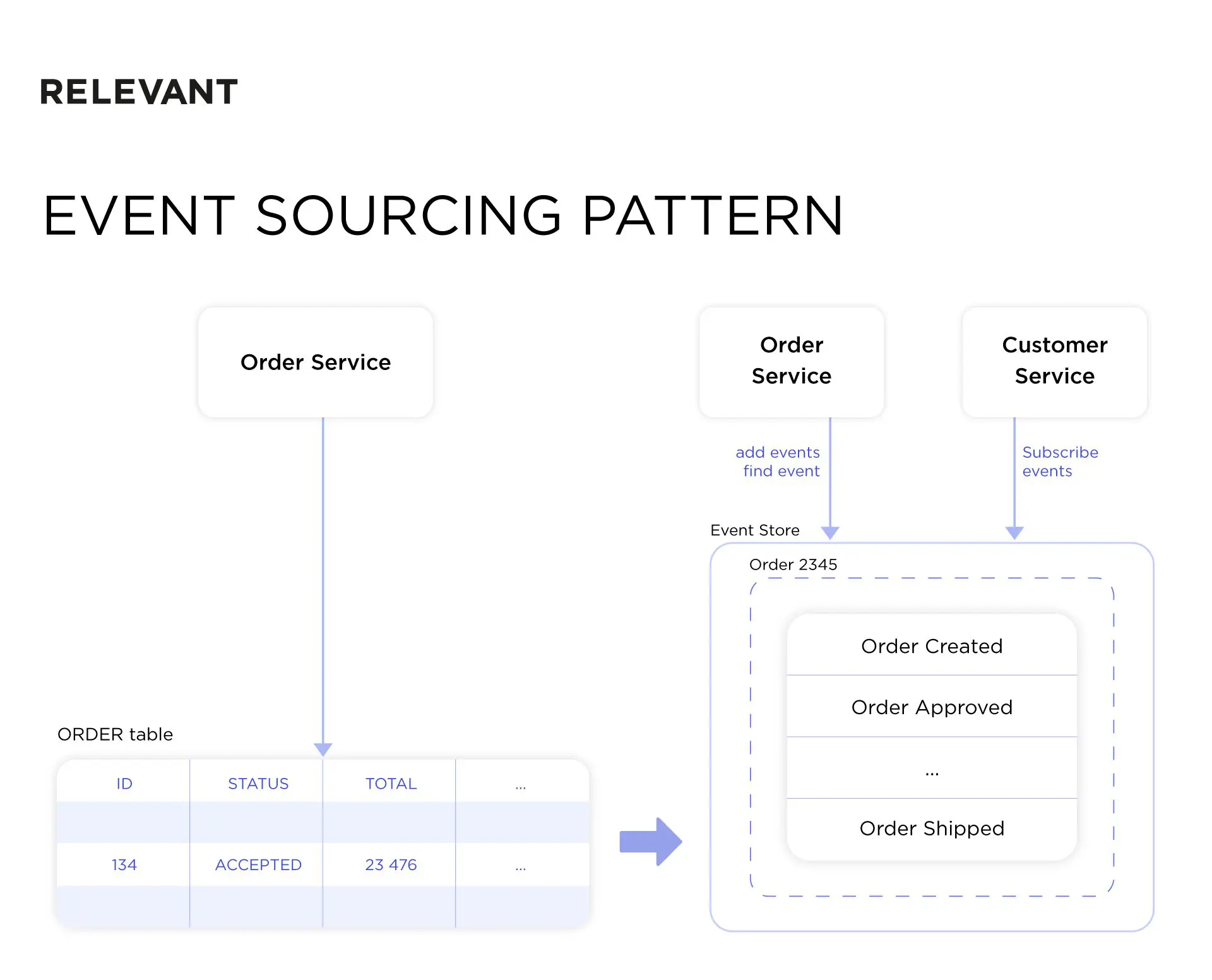
The Event Sourcing pattern
Using Saga creates the need for event sourcing. The Event Sourcing model captures and stores data alterations as event sequences. Every time there’s a change, an event gets logged. Then, to understand the current state of any data, the application simply replays these events in order. An event store uses API to insert and retrieve an aggregate’s events. And it also uses API for subscribing to events, similar to a message broker.
Take a look at the application built with event sourcing and the CQRS patterns. Here’s how it persists orders. Every order is stored as a sequence of events, and the customer store subscribes to them.
The Shared Database anti-pattern
Certainly, integrating a database for microservices is possible and within reach. You can establish a single unified database, allowing each service to access data via local ACID transactions. If this is truly on your agenda, take a moment and give it a thorough second thought.
With a single shared database, you risk losing all the best microservices features, like loose coupling and service independence. With one database, it’ll take you more time to coordinate services. Even more, services can have run-time problems and block each other. Also, if a shared database goes down, so will the system. Just be sure to make the database resilient.
How to select a database for microservices
Today, the microservices database landscape offers plenty of options. But how do you pick the ideal fit for your application? First, start by picking the right database strategy and models. Let’s look at the two of them.
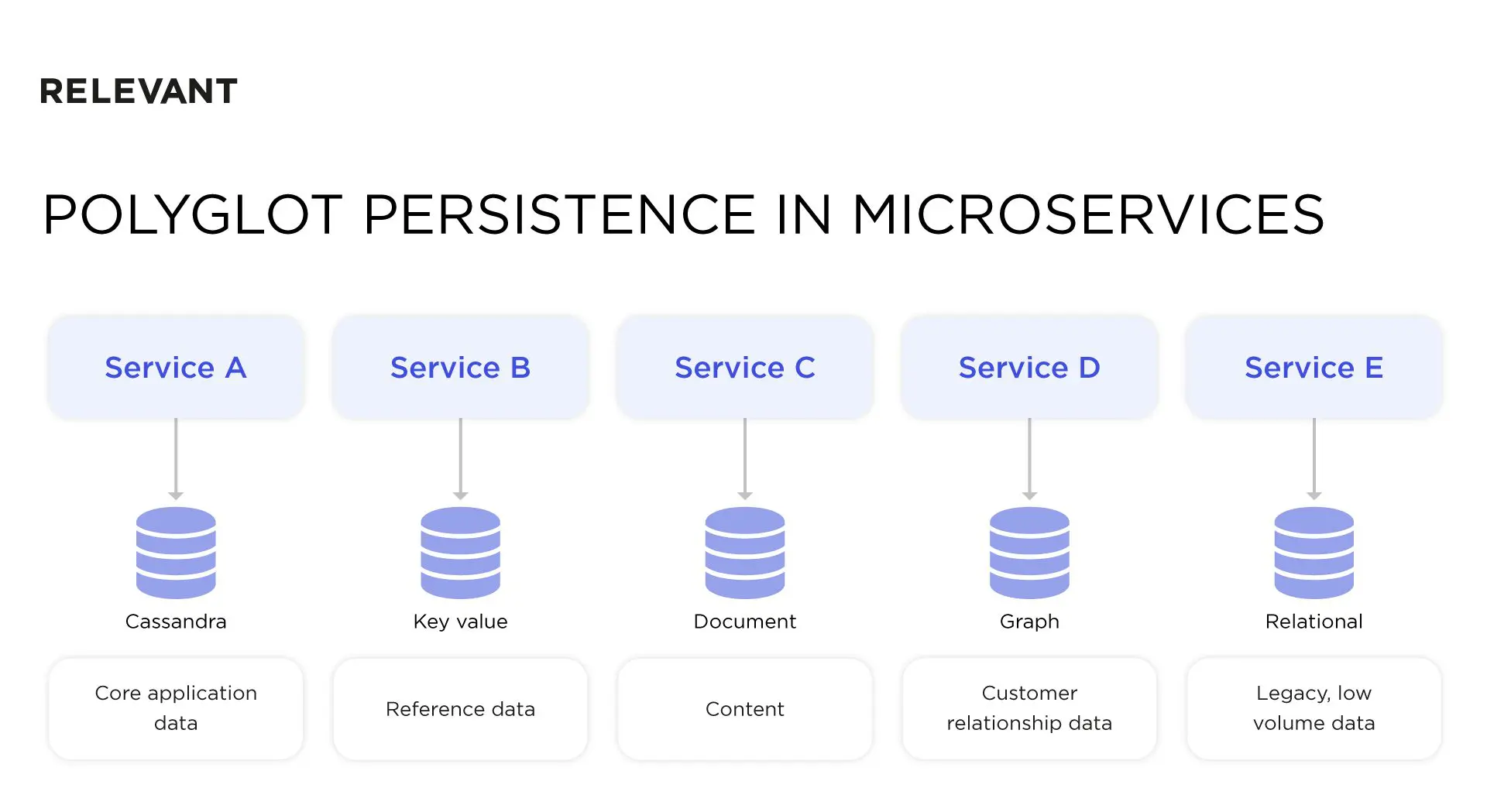
Polyglot persistence
The microservices architecture database enables the use of different kinds of data storing technologies for different services (aka applying polyglot persistence). Put simply, developers can opt for the persistence tech that aligns with their service best.
Interestingly, you can build a service that sits on top of multiple databases. The question is, what for? Thus, you’ll have multiple small services instead of a large and bulky one.
Multi-model databases
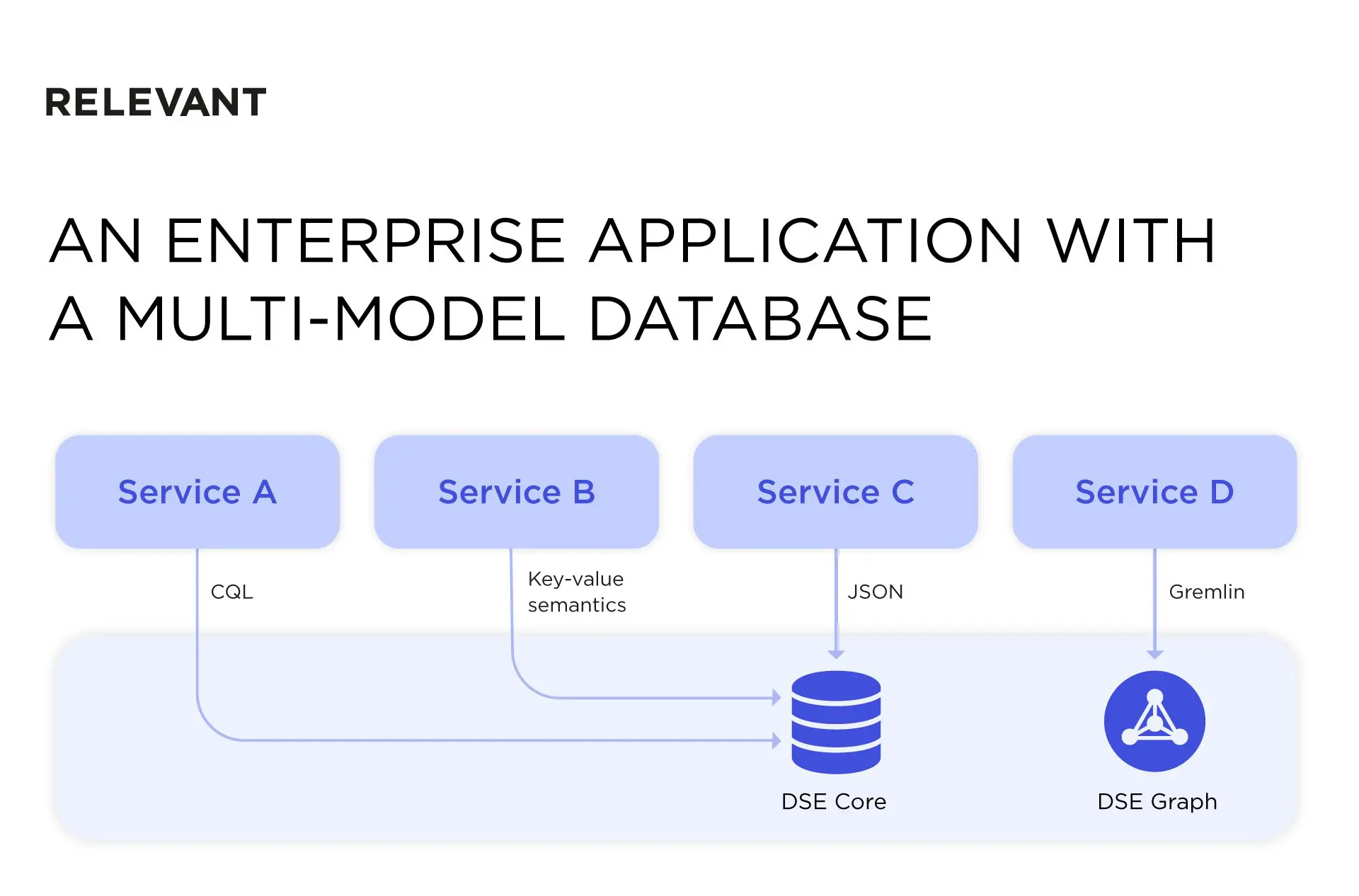
Another viable approach is selecting the multi-model database strategy. It allows a database to support more than one abstraction. In other words, you can have one multi-model database but different data models for each service, such as key-value, graph, tabular, etc.
For instance, look at an enterprise application. We have an app with Cassandra’s data model (partitioned row store) in the core and a DSE Graph on top of it. There’s one core database but with distinct layers on top of the DSE Core tailored to various services.
The multi-model approach offers what polyglot persistence can’t – operational simplicity. When you only have one microservices management platform, it’s easier to manage the system, even if each service has its model of interacting with data. On the other hand, polyglot persistence fits microservices perfectly, and if your application isn’t too complex, it’s better to stick with it. On a brighter note, you can easily use both models across multiple services.
Now, you’ve reached the point where you should choose a database technology for microservices. How? Just ask yourself what kind of data you need to store and how you plan to support microservices database management.
Non-relational databases
Let’s look at some non-relational databases (NoSQL) that correspond to different types of stored data and data models. In microservices, you can combine several of those.
Document databases
The databases of this type handle data in a JSON-esque manner. Document databases offer an intuitive data model. In other words, documents map to the objects in the application code. So, you don’t need to run JOINs or decompose data across tables. Plus, their distributed nature ensures system scalability.
Document databases are perfect for content management and storing catalogs. For instance, you can apply it in a blog application or an e-commerce platform. Popular document databases are MongoDB and Cloudant.
Key-value databases
A key-value database is like a digital locker system that stores data as a group of key-value pairs. Each piece of data, or “value”, is stored with a unique key, much like a locker number. If you want to access the data, simply use the key to retrieve it. The key-value data store suits session-oriented applications best because it can quickly process large amounts of session-related data. The well-known key-value databases are Redis, Amazon DynamoDB, and Oracle NoSQL.
Graph-based databases
A graph database uses the graph data model in which data entities are connected in nodes and form relationships stored in edges. The main value of a graph is to store and navigate those relationships. We usually apply graph databases for detecting fraud, powering social networks, and driving recommendation systems. OrientDB, Neo4j, and Amazon Neptune are just a few examples of graph databases you can use.
Column-based databases
As the name suggests, a column-based database stores data in columns rather than rows. Imagine a bookshelf where you can quickly grab all the titles without pulling out every book. This setup allows you to access the necessary data more accurately and faster since you can simply use a column name without scanning the unrelated row data. Such databases are ideal for building a data warehouse or processing Big Data. Check out Apache Cassandra or Apache HBase if you’re looking for a column-oriented database.
Relational databases
You shouldn’t consider using a single relational database if you are building a microservices application from scratch. But you’ll have to work with one if your app already exists and it’s a monolith. In that case, switching to microservices principles of database management will mean you can’t abandon the old infrastructure at once. You’ll have to start building microservices with what you have – a relational database, such as DB2, MS SQL Server, MySQL, or PostgreSQL, and gradually split it into several small services.
On top of that, you can use a relational database in microservices if you apply polyglot persistence. A relational database is an excellent fit for a service that manages low volumes of stable data.
Summary
If you want to have a solid system, you need to establish strong microservices database management and ensure every data point is in harmony. Start by choosing data-related patterns. Next, you should leverage different approaches to creating data stores and models. Finally, you can pick a microservices database that best matches each service’s needs. In such a way, you will build a stable and efficient system.
And if you get lost on your way, contact Relevant Software. Our expert team will help you build a resilient and robust microservice database architecture for your application.


