
Machine Learning Software Development: Insights from the Pros
 Anna DziubaVP of Delivery at Relevant Software
Anna DziubaVP of Delivery at Relevant SoftwareRight now, machine learning software development isn’t just some niche idea people are realizing within their basements; it’s a huge deal. The whole world of machine learning is expected to jump to a jaw-dropping $354 billion by 2027. From healthcare, where it helps doctors tailor treatments to each patient, to banking, where it’s used to spot suspicious activity, machine learning is everywhere.
In essence, what is machine learning (ML) described simply? Need to say, the concept is quite intuitive. While AI enables machines to exhibit human-like intelligence, ML, as its subset, focuses on data-driven learning and optimization. Interestingly, our most compelling developments in AI are related to machine learning. Ascertain how we attained this by inspecting our topic related to machine learning in software development.
What is Machine Learning Software Development?
From the point of software development, machine learning involves the art of designing, building, and deploying software systems that leverage machine learning algorithms to autonomously analyze and interpret complex data sets. These systems can learn from the data and make decisions or predictions without being overtly programmed for these tasks.
Unlike traditional software that operates on direct instructions for every possible scenario, machine learning software develops its understanding from the analysis of data. It’s a bit like giving your computer a brain that grows smarter the more it “practices.”
Fundamentals of Machine Learning Software Development
We shall not dissect the finer points of machine learning, considering we have addressed it in our blog already. In our discussion, we’ve given precedence to the credos we utilize to engineering machine learning systems that are robust, effective, and performant.
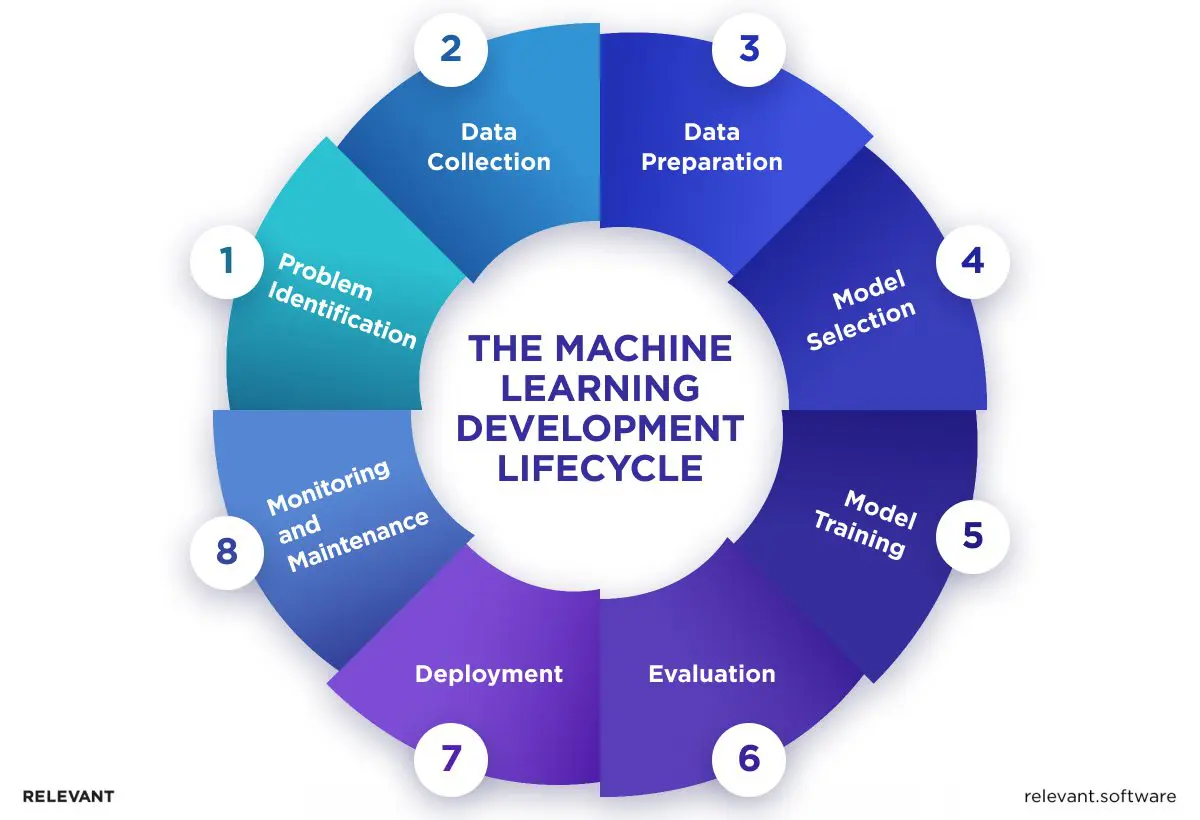
The Machine Learning Development Lifecycle
The machine learning development lifecycle is a structured process that guides the transition from raw data to a deployed machine learning model. Initially, it involves the selection of appropriate data sets for training and testing the algorithms. This phase is crucial because the model’s effectiveness and precision are directly shaped by the richness and variety of the data.
Subsequently, machine learning software engineers choose an algorithm suited to the task at hand, ranging from simple linear regression for predictive analysis to complex neural networks for image and speech recognition.
Another essential aspect is the iterative process of model training, testing, and tuning, which refines the algorithm’s ability to generalize from the training data to real-world scenarios.
Lastly, the integration of the trained model into existing software frameworks marks the culmination of the development process, enabling the practical application of machine learning innovations.
Related – Machine Learning App Development: A Professional’s View
Key Tools and Technologies
The toolbox of software development machine learning is rich with programming languages such as Python, which offer robust libraries and frameworks like TensorFlow, PyTorch, and Scikit-learn to streamline the development process. TensorFlow and PyTorch are instrumental for deep learning applications, offering flexible platforms for designing, training, and deploying complex neural networks. Scikit-learn is renowned for its extensive kit for traditional machine learning, including classification, regression, and clustering algorithms.
Working with Data
The foundation of any machine learning project is data. The process of working with data involves: 1) data collection, or accumulating data from various sources that accurately represent the problem space, and 2) data cleaning and preprocessing to ensure the quality of data by removing outliers, handling missing values, and transforming the data into a format that is usable for the model.
Through the application of these principles, machine learning software engineers not only achieve their immediate goals but also set the stage for a future where software is not just used but is capable of learning, evolving, and making decisions in increasingly human-like ways.
Designing Machine Learning Systems
This part presents the principles directing the building of these advanced systems, ensuring they solve current challenges and are primed for future advancements.
Architectural Patterns for ML Systems
In the task of building robust machine learning systems, selecting the right architectural pattern is crucial. It lays the groundwork upon which all functionalities depend. We will explain two prominent patterns that are pivotal in modern ML system design.
Microservices for ML
The microservices architecture is a design approach where a single application comprises many loosely coupled and independently deployable and scalable smaller services. This modularity provides a perfect basis for incorporating ML models into software systems. Imagine an e-commerce platform using separate microservices for recommendation engines, fraud detection, and customer sentiment analysis. Each service can evolve based on specific data inputs and usage patterns, enhancing the platform’s responsiveness and efficiency.
Serverless architectures
The serverless paradigm is remodeling how we deploy machine learning models, emphasizing the execution of code in response to events without the need to manage servers. This architecture is particularly suited for ML systems that need to scale dynamically. Machine learning engineers can focus on the model itself rather than the infrastructure, facilitating a more agile development process and thus lowering operational costs. For instance, an image processing application can utilize serverless functions to handle varying loads of image uploads without worrying about provisioning or scaling the underlying compute resources.
Integrating ML Models into Software Products
The integration of ML models into software products includes embedding algorithms and ensuring they deliver value through seamless interaction with user-facing applications.
API Development for Model Serving
The process often involves the development of Application Programming Interfaces (APIs) that serve as pipelines for data to flow between the models and the application’s core functions. These APIs enable applications to query ML models in real-time, feeding them input data and receiving predictions or analyses in return. Designing these APIs with efficiency in mind ensures that the added functionality of ML models does not come at the expense of the application’s performance. Furthermore, a well-designed API can make it easier to update or replace an ML model without significant changes to the application itself.
Ensuring Scalability and Performance
Machine learning in software development involves not just the initial deployment but also monitoring the system to adapt to changing demands. Effective scalability strategies might include leveraging cloud resources, optimizing model efficiency, and implementing load-balancing techniques. For example, a financial analysis tool that uses ML to predict market trends must handle spikes in demand around market openings and closings, requiring a scalable infrastructure that can maintain high performance under varying loads.

Best Practices in Machine Learning Software Development
In the domain of machine learning software development, adherence to best practices is not merely a procedural formality but a cornerstone of creating solutions that are both innovative and sustainable.
Ensuring Model Accuracy and Reliability
Developing machine learning software is replete with challenges that require a scrupulous approach to overcome. Among these, ensuring the accuracy and reliability of models, alongside safeguarding data privacy and security, stand paramount.
Techniques for model evaluation and validation
The foundation of any machine learning model lies in its ability to predict outcomes accurately and reliably. This involves a strict process of evaluation and validation, ensuring the model can navigate the vast datasets it encounters. Cross-validation, a technique where the dataset is partitioned into subsets, some of which are used for training and others for testing, ensures that our model is not just memorizing the data but truly learning from it.
Handling overfitting and underfitting
Sailing too close to the data (overfitting) or too far from it (underfitting) can be perilous. Overfitting is like being ensnared in a maelstrom, where the model performs exceptionally on training data but cannot generalize to new data. Underfitting, on the other hand, is akin to setting sail without a map, where the model fails to capture the underlying trends of the data. Techniques such as regularization, pruning, and selecting the right model complexity are likely to find the right sailing path, ensuring the model is robust and adaptable.
Security Considerations
In an era when data breaches are not uncommon, data privacy and model security are of the utmost importance in software development machine learning.
Data privacy and model security challenges
Considerations here encompass safeguarding the data used to train models and ensuring the models themselves are not vulnerable to attacks. Techniques like data anonymization and differential privacy act as encrypted maps that keep the location of the treasure safe. Meanwhile, securing the ML model includes fortifying it against adversarial attacks to make it robust in the face of attempts to deceive or corrupt its predictions.
Compliance with regulations (e.g., GDPR, HIPAA)
Compliance with frameworks like the General Data Protection Regulation (GDPR) in Europe or the Health Insurance Portability and Accountability Act (HIPAA) in the United States is not just about legal obligation—it’s about building trust. These regulations ensure that machine learning software development respects user privacy, consent, and data protection, which is essential in a world increasingly wary of digital intrusion.
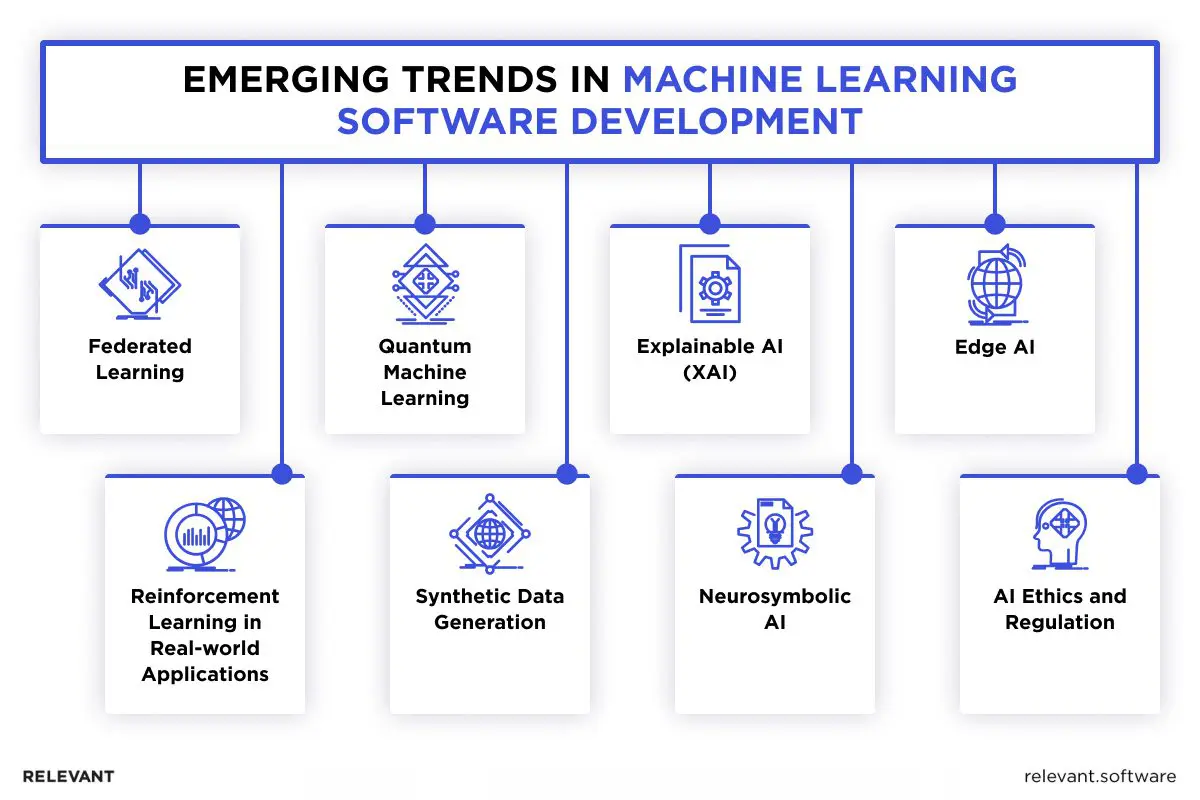
Machine Learning Software Development: Emerging Trends
The field of machine learning software development is witnessing the rise of trends that are streamlining processes, enhancing efficiency, and democratizing access. Among these, AutoML and ML Ops stand out for their transformative potential.
AutoML, or Automated Machine Learning, simplifies the painstaking process of selecting the right model, tuning hyperparameters, and preprocessing data. This makes it accessible to a broader range of professionals, thus accelerating innovation across industries.
ML Ops (Machine Learning Operations) integrates machine learning models into the broader IT operations, ensuring that models are not only developed in a vacuum but are seamlessly monitored and maintained within production environments.
Other evolving trends in the sector will be briefly summarized in the visual below.
Build an ML Software with Relevant
Generic AI and machine learning solutions often fall short. So, to succeed, you need to engage a machine learning software development agency that understands your unique needs, clarifies your objectives, and delivers software to meet those challenges.
At Relevant Software, we offer a clear, no-nonsense collaboration that respects your time, focusing on delivering results that matter. Here’s a concise roadmap to creating impactful ML applications:
- Vision and Objectives: We start with a clear understanding of the problems you aim to solve. This guides every step of the process of machine learning software development.
- Data Collection: We gather relevant datasets that will train your models effectively.
- Selecting Tools: We choose the appropriate ML frameworks and tools that align with your project’s requirements, optimizing development time and effectiveness.
- Model Development: We develop and train your ML model, iterating to enhance performance.
- Integration and Deployment: We seamlessly integrate the ML model into your existing infrastructure, focusing on scalability and reliability for real-world applications.
- Continuous Improvement: Post-launch, our machine learning software development agency specialists continually refine and update your model to maintain its effectiveness and adapt to new data.
With a focus on practical steps, cutting-edge technology, and continuous innovation, your path to deploying impactful ML software is clearer and more achievable than ever. Contact us to start!


