LLM Security: How to Safely Use Large Language Models in Your Business
 Vadim StrukProduct Manager and Head of Business Analysis at Relevant Software
Vadim StrukProduct Manager and Head of Business Analysis at Relevant Software
What happens when smart systems behave in ways no one expects? That’s the question many teams face as large language models (LLMs) move from experiments to daily operations. These models help draft emails, summarize documents, and answer complex questions fast and fluently. But their power comes with new forms of risk. LLM security now matters because these models operate unpredictably, often in ways experienced teams fail to anticipate.
This LLM security paper breaks down what that means in practice. From data exposure to hallucinated outputs and unsafe API calls, it outlines the risks that emerge once models scale. It also offers a clear path forward: how to design, integrate, and monitor LLMs with safety in mind. For teams building enterprise-grade systems, our AI software development services provide the support needed to protect systems while keeping them flexible and effective.
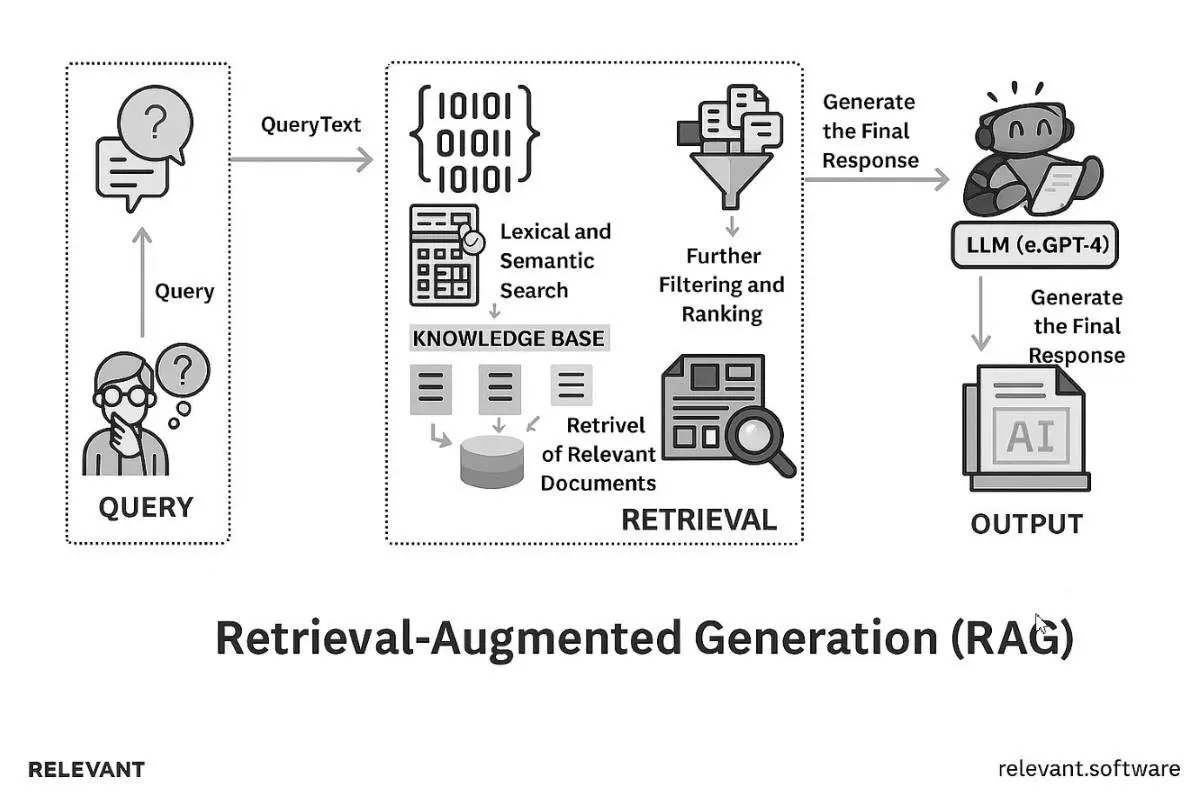
What is LLM security, and why does it matter
Large Language Models like GPT-4, Gemini, and Claude now play a quiet but central role in how many teams work. They can be used for chatbots, search engines, writing assistance, and even software development. Their responses often feel natural and tailored, making once-complex tasks, like summarizing reports or translating documents, faster to handle.
But the same flexibility that makes these models useful also brings unfamiliar risks. Unlike traditional software, large language models do not follow fixed logic or draw answers from a defined database. Instead, they generate responses based on statistical patterns in their training data. This design creates a new set of challenges. A model might echo sensitive internal language, respond to subtle prompt manipulations, or produce output that feels accurate but lacks factual grounding.
Security in this context requires more than firewalls or encryption. It demands a full-system view of how models receive data, how they behave, and how outputs move through applications. LLM security provides a framework for managing LLM risks. It spans four critical layers:
1. Data layer
Manage the information that reaches the model. Tag sensitive content, reduce unnecessary exposure, and apply prompt filtering or redaction where needed. Internal studies show that exposure often comes from routine interactions, not isolated incidents.
2. Model layer
Strengthen the model’s ability to handle unsafe inputs. Use prompt validation, response filtering, and adversarial testing to defend against injection attacks and jailbreaks. Recent security audits confirm that even leading models respond to manipulation when left untested.
3. Integration layer
Control how the model connects with other tools. Limit API access to essential functions, apply scoped permissions, and define clear usage boundaries. These steps help prevent accidental actions and contain the impact of any unusual behavior.
4. Governance layer
Establish oversight across the system. Identify who manages AI usage, how data flows through each component, and which environments host LLM tools. A recent report from Harmonic security revealed that 45,4% of sensitive GenAI usage occurred through unmanaged channels such as personal accounts, clear signals for improved visibility and accountability.
Why LLM security should be a business priority
For many companies, AI integration represents a leap in capability. But behind the rapid progress lies a shift in how systems behave, and how security must respond. Unlike earlier enterprise software, these models don’t run on business logic alone. They interpret language, guess intent, and build responses in real time.
When left unchecked, this behavior introduces a new kind of fragility.
The new risks that come with smart models
An LLM does not retrieve facts from a database. It generates responses that sound plausible. That difference matters. A user might ask a simple question, and the model could respond with outdated or incorrect information. It might even echo sensitive content if it was included during training. When models can’t explain where their answers come from, there’s no easy way to verify accuracy or detect hidden exposure.
Even well-tested applications can go off-track when inputs change or users behave in unexpected ways. Prompt injection, model manipulation, and misuse of context windows are not fringe problems. They already appear in production systems today. And as adoption grows, so does the surface area for attack.
Real-world consequences of ignoring LLM security
When companies underestimate the impact of LLM vulnerabilities, the consequences often show up fast. A chatbot might reveal internal business logic during a routine user session. A customer-facing tool could generate misleading financial advice. In healthcare or finance, even a small mistake may lead to fines, reputational loss, or legal scrutiny under frameworks like GDPR, HIPAA, or PCI-DSS.
Every LLM security failure becomes a trust issue. And trust, once lost, is difficult to regain. Based on Relevant Software experience, these failures rarely stem from technical flaws alone; they often result from unclear ownership, missing controls, or assumptions about model behavior. For teams building with these systems, the real challenge lies in establishing the right safeguards before users ever interact with the product.
Key security risks when using LLMs
As large language models become embedded in internal tools and customer-facing platforms, the risk surface grows. They no longer operate in isolated labs. They sit inside help desks, onboard new hires, summarize contracts, and analyze user behavior. And while their fluency is impressive, their architecture creates challenges that require new thinking.
Below are five critical LLM security risks that enterprise teams must account for.
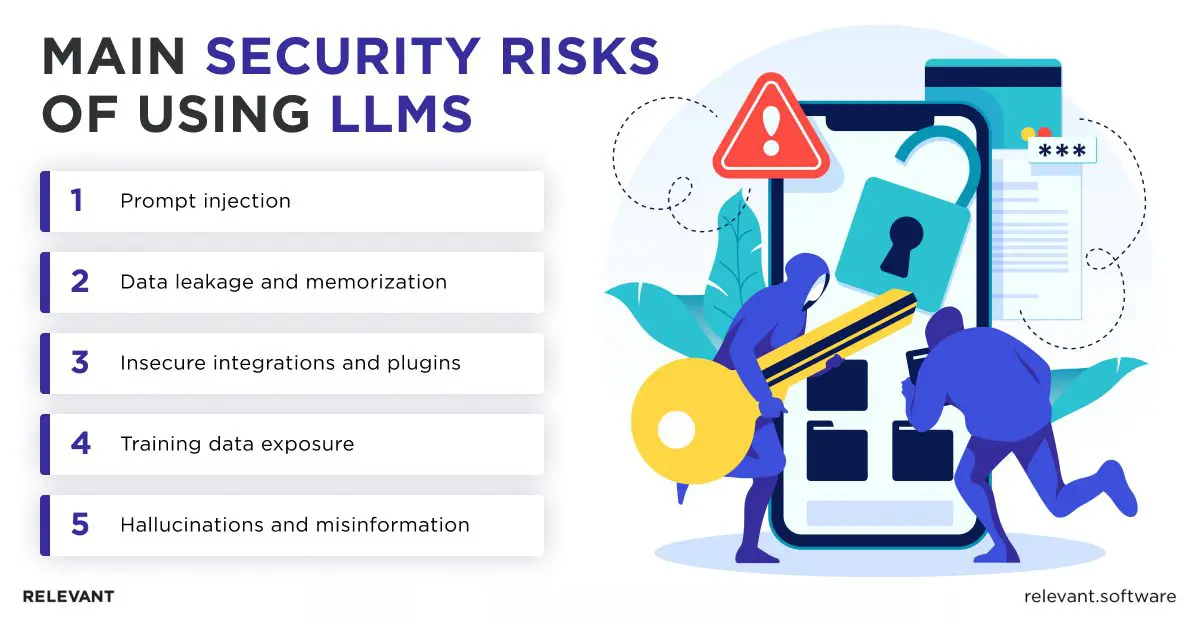
1. Prompt injection
At its core, prompt injection is about manipulation. Someone inserts hidden commands into an input field, often in ways that seem harmless, and the model interprets those commands as part of its instructions. This can happen through text pasted from emails, feedback forms, or even chatbot conversations.
Why it matters: If the model isn’t designed to spot or block these injected prompts, it might reveal internal information, bypass authentication steps, or perform actions it shouldn’t. In tools connected to APIs or backend systems, the impact can be serious; one cleverly crafted message could trigger an unwanted event or expose private content.
2. Data leakage and memorization
LLMs learn by training on vast datasets. If sensitive business data is used in that process without proper controls, fragments of that information can sometimes surface in outputs. A support chatbot might quote something from a private document. An internal assistant might reference outdated credentials.
Why it matters: Even a short phrase can contain personal data or confidential details. If that content reaches the wrong person, it’s more than a technical issue; it’s a potential compliance breach. Businesses operating under privacy laws like GDPR or HIPAA need to be especially cautious.
3. Insecure integrations and plugins
Today’s LLMs rarely work alone. They’re embedded into apps, websites, and backend systems. Many connect with APIs or use plugins to complete tasks. But these connections introduce new attack surfaces. If the integrations aren’t properly secured, a model could unintentionally act on a bad input.
Why it matters: Imagine a prompt that causes an LLM to cancel a user’s appointment, send a message on behalf of a manager, or access system logs. Without proper checks in place, the model becomes a gateway to sensitive systems, and attackers know it.
4. Training data exposure
Companies often fine-tune LLMs using internal documents to make the output more relevant. This improves results, but it comes with added responsibility. If that data isn’t filtered or securely stored, parts of it may bleed into responses.
Why it matters: Customers might see language that feels oddly specific. Employees may notice that a model “knows too much” about internal matters. Once private data is embedded in a model’s behavior, removing it is challenging, and explaining how it was exposed is even more difficult.
5. Hallucinations and misinformation
As Relevant Software experts point out, large language models can introduce risk even when no attack is underway and all data remains protected. They sometimes generate information that sounds right, but isn’t. These hallucinations happen because the model is predicting the most likely next words, not verifying facts.
Why it matters: A model might give wrong pricing information, misstate a legal term, or fabricate a source. And if a customer or employee acts on that answer, the fallout lands on the business. In regulated industries, these hallucinations are not minor glitches; they can become liabilities.
How to secure LLM use in your business
Securing LLMs takes more than testing outputs or scanning for bugs. True safety requires planning at every stage, from how the model is integrated to how its behavior is monitored over time. These practices reflect what we’ve seen across examples of AI in cyber security, where automation and real-time analysis enhance detection but still require strict safety controls.

Limit model permissions with a least privilege approach
Start by restricting what the model can access. Avoid connecting it to live APIs, user databases, or automation systems unless absolutely necessary. Narrow access reduces the blast radius of a potential prompt injection or configuration flaw.
Use guardrails and output-level filtering
Implement validation layers to control how inputs are processed and how outputs are handled. Whether you use custom tools or platform-based filters, these controls help keep generated responses aligned with your policies and goals.
Avoid exposing sensitive data without clear safeguards
Models should never have unrestricted access to private or sensitive data. Encrypt prompts, remove unnecessary identifiers, and work with vendors that guarantee data isolation. Data sent to an LLM should be treated with the same scrutiny as production logs or customer records.
Add human review for high-stakes decisions
In sectors like healthcare, finance, or legal tech, models should support, not replace, expert judgment. Flag critical tasks for human review and create escalation paths where needed. This adds friction in the right places and reduces reliance on unverified outputs.
Select vendors with proven security practices
Vet LLM vendors for compliance, transparency, and reliability. Look for published security documentation, SOC2 or ISO certifications, and a history of responsible updates. Secure outcomes begin with secure foundations.
LLM security best practices checklist (for teams)
Knowing the risks is only part of the solution. Maintaining LLM application security across your systems, people, and workflows requires consistent execution. This checklist from Relevant Software experts outlines practical actions your team should take to reduce LLM-related risks before the next deployment affects your supply chain, exposes sensitive information, or undermines AI security standards.
✅ Have we reviewed where and how LLMs are used internally?
Visibility is step one. Identify every place your LLM model is active, whether it supports customer service, helps write reports, automates ticket summaries, or powers internal search. Track how each tool interacts with data sources and clarify ownership to prevent uncontrolled growth or hidden exposure.
✅ Are inputs and outputs being logged and monitored?
Generative systems behave unpredictably. Secure logging supports detection of data breaches, hallucinated output, or policy violations. It also creates a feedback loop for better risk management and prepares teams for DoS attacks or post-incident audits.
✅ Are we using open-source or vendor tools to test for prompt injection?
Prompt injection is not theoretical; it is active across many enterprise environments. Use purpose-built testing frameworks or leading tools from LLM security startups and vendors. These simulate threats and verify that your system handles malformed input, prompt chaining, or escalation attempts.
✅ Do we have a policy for acceptable use of public vs. private LLMs?
Not all LLM providers offer the same security posture. Some may log inputs or fail to encrypt data at rest. Define when private models are required, especially for high-sensitivity use cases, and treat public models as external dependencies with added safeguards. These decisions directly impact your competitive advantage and exposure to third-party risk.
Questions to ask your AI or Dev team today
Even the most advanced LLM security tools cannot protect your business if internal awareness is low. Use the following questions to guide a structured conversation with your AI, DevOps, or platform engineering team. Each question can help surface overlooked LLM security vulnerabilities and clarify ownership before small missteps evolve into security incidents.
1. What large language models (LLMs) are in use today, and where?
Go beyond the obvious tools. Are generative AI features embedded in customer support chatbots, document search, BI dashboards, or internal developer tools? Clarify whether these are foundation models, open-source LLMs, or hosted vendor APIs. This inventory is the foundation of any effective LLM security strategy.
2. What types of data are being shared with each model, and how are those inputs managed?
Are prompts or data streams passing through sensitive customer information, financial records, or internal IP? If so, has the team implemented anonymization or restricted access? This speaks directly to LLM data security and helps prevent data leakage or compliance violations.
3. Do we regularly evaluate model outputs for bias, misinformation, or legal risk?
LLMs can hallucinate, fabricate sources, or return inappropriate results. Model monitoring should include both technical and human-in-the-loop review processes, particularly in regulated domains like healthcare, finance, or legal. If these checks are missing, LLM safety cannot be assured.
4. Who holds responsibility for LLM cyber security within the organization?
Security gaps often appear when ownership is unclear. Identify who manages risk assessment, vendor review, output auditing, and integration testing. If multiple teams touch the model, clarify how coordination happens. Define whether this falls under engineering, cybersecurity, compliance, or a hybrid role. Many mature companies now appoint a dedicated LLM application security lead.
5. Do we use any tools or frameworks to simulate LLM attacks or validate behavior under stress?
LLM security testing for prompt injection, unauthorized access, or API misfires is critical. Ask whether the team has explored large language model security testing tools or applied guidance from frameworks like LLM security OWASP. Active security testing is where many leading LLM security providers differentiate themselves.
AI safety with Relevant Software
When companies begin using large language models, security gaps often appear where no one expects them. A model answers a question it shouldn’t. An internal tool shares data too broadly. A plugin acts without proper oversight. These risks don’t come from bad intentions; they come from missing structure.
Relevant Software clients, ranging from global enterprises to fast-scaling startups, rely on our software security services to close these gaps before they affect users. Our team builds AI systems with safeguards that matter: access controls that limit exposure, prompt design that reduces leakage, and clear workflows with review built in. From model selection to production deployment, we guide every step with security in focus.
Whether you plan to use LLMs in a customer-facing product or an internal workflow, our focus remains the same: make it secure and make it sustainable.
Contact us to build with confidence!