Enterprise Data Warehouse: How to Build a Scalable Data Foundation
 Ostap DribniukSenior Software Engineer
Ostap DribniukSenior Software Engineer
If three teams can produce three “correct” answers, the business pays twice: first, through delayed decisions; then, through rework when audits or quarter-close expose gaps. A custom enterprise data warehouse addresses the root cause by standardizing definitions, enforcing governance, and maintaining performance stability as systems and organizations evolve.
This guide explains how to design an EDW (enterprise data warehouse) that remains fast and controlled as the business grows, with a delivery approach suited to complex enterprises. If you want a clean starting point before implementation, Relevant Software’s data strategy consulting services help you to clarify ownership, source rules, and the target architecture.
With that baseline set, the next step is simple: define what an EDW is and what it must do for your teams.
What is an enterprise data warehouse?
If meetings still include “our numbers look different,” the EDW system’s job is already clear. An enterprise data warehouse consolidates structured data from the systems that run the business and aligns identity, definitions, and time rules. Hence, teams work from a single metric layer across tools.
Here is the enterprise data warehouse definition in practical terms: a governed analytics foundation that ensures consistent reporting across teams, even as the source landscape evolves.
Organizations invest in enterprise data warehousing when reporting has consequences, and the platform must behave predictably under load. In practice, that means it supports executive reporting, forecasting that remains comparable cycle to cycle, regulated outputs with traceable paths back to source records, and cross-functional analytics that remain meaningful after M&A or system changes.
A modern data warehouse also assumes constant change. Schemas evolve, late data arrives, and new systems appear. Reliability comes from clear source rules, controlled transformation logic, and access policies that teams can show during reviews without improvisation.
Enterprise data warehouse vs data lake vs lakehouse
This decision determines whether your platform produces a single metric layer or a stack of parallel truths. Each of these types of data warehouses addresses a different problem, so mature enterprises often combine them with clear boundaries.
- Enterprise data warehouses fit best when you need curated, modeled datasets with predictable performance and controlled definitions, especially for finance-grade metrics and regulated reporting.
- A data lake fits best when you need low-cost storage for raw and semi-structured data, long retention, and flexible exploration. Trust is challenged when teams reuse raw outputs as reporting inputs without standards.
- A lakehouse fits best when you need BI and ML on the same foundation with stronger management than a classic lake. Platforms such as Databricks often sit here when teams want governed tables on open formats plus ML workflows.
If you want a clear recommendation tied to your environment, treat it as a build vs buy decision, not a tool comparison. That is also where enterprise data warehouse vendors differ: some sell platforms, others help you define and enforce the metric layer that makes the platform valuable.
When enterprise data warehouse solutions make sense
Enterprise data warehousing becomes the right choice when the business cannot afford “two versions of the truth,” and when reporting outcomes affects close, governance, or executive decisions. Most enterprise data warehouse tools create value by reducing reconciliation effort, maintaining consistent definitions as applications evolve, and providing traceability from metrics to source data. A modern enterprise data warehouse also absorbs new systems after growth or M&A without disrupting KPIs.
In that context, vendors fall into two categories: companies that sell enterprise data warehouse software, and partners that help you design the rules and operating model that keep the platform reliable.
- Regulatory environments. If audits, regulators, or internal controls require evidence, the EDW provides controlled access, lineage, and repeatable reporting outputs.
- Financial reporting accuracy. If close cycles depend on consistent definitions for revenue, margin, and adjustments, the EDW prevents logic drift across reports and reduces last-minute fixes.
- Enterprise-wide metrics consistency. If product, operations, and finance need to rely on the same KPIs across regions and business units, the EDW centralizes metric logic, preventing teams from building parallel versions.
- Data governance maturity. If the organization can assign ownership, agree on source rules, and maintain change control, the EDW becomes a stable platform rather than another reporting layer.
Now, let’s walk through the core building blocks of the enterprise data warehouse architecture.
Core components of an enterprise data warehouse architecture
Think of an EDW like a factory line for numbers inside a larger data ecosystem. Raw data enters from business systems, moves through controlled steps for data transformation, and then lands in structures that stay fast under load and consistent over time. A simple enterprise data warehouse diagram typically shows five blocks: sources, ingestion, transformation, storage, and a semantic layer, with governance wrapped around them. Together, these enterprise data warehouse tools support reliable data analysis on shared definitions.
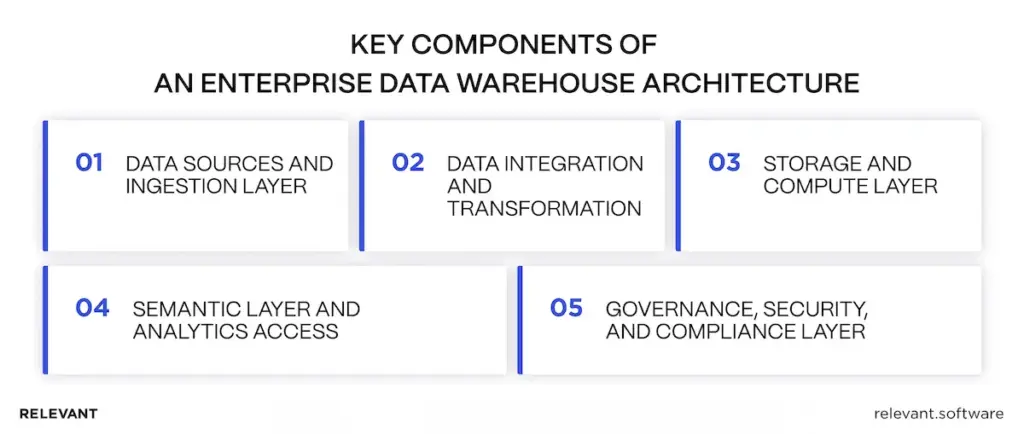
1) Data sources and ingestion layer
This is the “intake” step. The EDW pulls data from systems such as customer relationship management, ERP, billing, support, and product databases. The job here is to reliably move data through data pipelines and detect issues early, before they manifest as broken reports.
In a simple setup, data is delivered directly to the warehouse. In a heavier setup, teams first use an operational data store as a staging area for near-real-time data, then move validated data into the EDW so downstream consumers rely on stable inputs.
2) Data integration and transformation
That is the “make it usable” step. Raw data rarely matches across systems, so this layer ensures consistency through repeatable data transformation.
Here’s what happens in this layer: the platform runs data cleansing, standardizes names and codes, and applies one set of rules for time and identity across sources. That is where “customer” becomes a single definition across CRM and billing, and where “last quarter” follows the same calendar in every report. The team also builds the data model here, using database normalization to reduce duplication and strengthen data integrity.
When teams need pattern discovery on top of curated datasets, they can layer controlled data-mining workflows here as well. Still, the EDW keeps reporting-grade logic separate from experimentation, so the core metric layer remains stable.
3) Storage and compute layer
This is the “where it lives and how fast it runs” step. The EDW stores cleaned, structured, and query-ready data, including historical data, so analysts and BI tools can compare performance across months, quarters, and post-merger periods without redefining logic.
In cloud data setups, teams often separate compute resources for loading, transformation, and reporting to avoid slowing pipelines from heavy dashboard traffic. The goal is to maintain predictable performance, especially when many people query the system simultaneously.
4) Semantic layer and analytics access
This is the “stop the metric drift” step. If every dashboard calculates revenue differently, the EDW still fails. The semantic layer defines KPIs once and reuses them across all layers.
It provides business intelligence tools with the same definitions for metrics and dimensions, ensuring reports match across teams. That is where self-service becomes safe because people can explore without rewriting core rules, while still getting consistent results from the same governed metric layer.
5) Governance, security, and compliance layer
This is the “control and proof” step. It determines who can access sensitive fields and shows the source of the numbers.
Good data governance includes role-based access, audit logs, and lineage from source to report. That matters in regulated environments and in large companies because ownership and change control prevent the platform from drifting over time, even as new sources join the data ecosystem.
Common enterprise use cases for data warehousing
An EDW earns its budget by supporting work that people will challenge, with a consistent history and clear definitions that hold up under scrutiny.
Executive reporting and performance management
Leaders need one view of performance across products and regions. An EDW helps because KPIs remain consistent month-to-month, even as source systems change, which keeps executive review cycles grounded in the same definitions.
Financial and regulatory reporting
Finance needs stable rules and a clean history, and compliance needs traceability. An EDW supports both by documenting transformations and controlling access, with a clear trail from source records to reported numbers that remains consistent across periods of historical data.
Customer analytics and personalization
Customer data is typically spread across multiple systems. The EDW connects identity and history, ensuring segmentation, cohorts, and lifecycle reporting remain accurate, which improves personalization without compromising trust or weakening data integrity.
Operational optimization
Operations data sits across tools and teams. The EDW connects it, enabling you to measure end-to-end flow, identify bottlenecks, and track SLAs with a single, consistent view that business owners can validate.
AI and advanced analytics enablement
AI needs stable training data. When definitions change, models break. An EDW provides consistent entities and time logic, plus governed access for data science. Some teams run ML workloads in Databricks but still need a clean EDW foundation to ensure features and evaluation datasets remain consistent.
If your outline later includes a comparison section, a short add-on line fits naturally there: “An enterprise data warehouse vs data mart comparison often comes down to scope: the EDW governs enterprise-wide definitions, while a data mart serves a narrower team or domain.”
Build vs buy: How to choose an enterprise data warehouse approach
This decision comes down to risk tolerance and complexity. Packaged options can deliver fast dashboards in stable environments. If reporting feeds board updates, close cycles, or regulated outputs, the approach must prioritize traceability and control from day one. Many teams buy a platform to move quickly, then add custom logic later because definitions, identity, and governance rarely fit out of the box.
Off-the-shelf platforms
Off-the-shelf platforms work well when the source landscape is limited, data stays stable, and reporting rules follow common patterns. Risk increases after acquisitions that create duplicate records, when regions require reconciliation logic, or when reviewers request a clear trail from source to report. At that point, teams bolt fixes onto the platform, and the early speed advantage fades.
Custom architecture
Custom enterprise data warehouse solutions fit when complexity is normal: multiple ERPs, fragmented CRM, entity hierarchies, region-specific rules, and strict governance. The value comes from clear ownership and source rules, tested and versioned transformations, and consistent metric definitions across teams.
This approach also applies when the EDW is part of a broader modernization program, such as cloud migration or enterprise system integration. In that case, teams often align delivery with enterprise software development services and treat the warehouse as a core platform work, not a one-off analytics project.
If you want a quick market scan before you shortlist partners, see Relevant Software’s guide to top data analytics companies.
How to build an efficient enterprise data warehouse
A fast EDW is not the one that ships first. A fast EDW keeps shipping without rewrites. The steps below focus on reliability and scale, while keeping delivery practical and measurable.

1. Define business objectives and data use cases
Start with decisions and accountability. Select the KPIs that leadership will challenge, then assign owners to each definition. This step prevents the common failure: a warehouse that runs, but never becomes trusted. Teams that need support translating business goals into a scalable EDW program often start with data analytics services.
2. Audit existing data sources and data quality
Inventory operational systems, SaaS platforms, legacy databases, and external feeds. Then look for what will break consistency: duplication, conflicting “source of truth” claims, undocumented business logic inside exports, and gaps that require reconciliation rules. Do this early, while the scope is still flexible.
Regulated industries show this risk clearly. The patterns in data warehousing in healthcare illustrate why identity, governance, and traceability must be designed early.
3. Design the target architecture and data model
Choose cloud, hybrid, or on-prem deployment based on scale, compliance, and latency. Define ingestion patterns that align with the business: batch (where stability is critical), streaming, or CDC (where operational visibility is critical). Select a modeling approach that fits your consumers, then plan a semantic layer to ensure metrics remain consistent across BI tools.
If the EDW must handle large event volumes and complex integrations, it often overlaps with broader big data solutions initiatives.
4. Build reliable data pipelines and transformations
Automate ingestion, validation, and schema evolution handling. Keep business rules centralized in the warehouse layer instead of embedding logic in dashboards. Version pipelines and transformations for traceability and rollback, design for idempotency, and include retry paths so failures do not cause silent data corruption.
To support implementation across ingestion, modeling, and operational reliability, teams often use data management services to keep pipelines production-ready.
5. Implement governance, security, and compliance controls
Apply role-based access and least-privilege policies. Add data lineage, audit logs, and change traceability for critical datasets. Use encryption, masking, and retention policies, and align controls with GDPR, HIPAA, SOC 2, or industry-specific requirements where needed. A well-designed governance layer also reduces “shadow reporting” by enabling teams to access what they need without workarounds.
6. Optimize performance and cost from day one
Design for peak load, not average usage. Use partitioning, clustering, and query optimization strategies that match real access patterns. Isolate workloads for analytics, ingestion, and experimentation, and add cost visibility to prevent growth from leading to unexpected spend.
7. Enable analytics, self-service, and data adoption
Make consistent metric definitions available through semantic models. Provide governed self-service access so teams move fast without breaking controls. Add documentation and a catalog that explains meaning and ownership, then onboard business users to drive adoption without metric drift.
8. Automate testing, monitoring, and continuous improvement
Add data quality tests, freshness checks, and schema drift detection. Implement pipeline observability and alerting, then use CI/CD for data infrastructure and transformations. Run regular optimization cycles based on actual usage and growth.
When an enterprise data warehouse becomes a strategic asset
From 2025 through 2030, investment patterns continue to reinforce the same point: enterprises now treat data as core infrastructure. Mordor Intelligence projects the cloud data warehouse market will grow to $49.12B by 2031, with a 26.86% CAGR over 2026–2031. Grand View Research projects that the data governance market will reach $12.66B by 2030. Gartner predicts that by 2029, 10% of global boards will use AI guidance to challenge executive decisions that are material to their business.
Relevant Software helps teams meet that bar with a senior-led blueprint, clear source ownership rules, and delivery plans that keep KPI logic consistent across tools. If reporting still requires manual reconciliation, book a short scoping call and get an execution-ready plan your team can run.